All about Structure: Adapting Structural Information across Domains for Boosting Semantic Segmentation
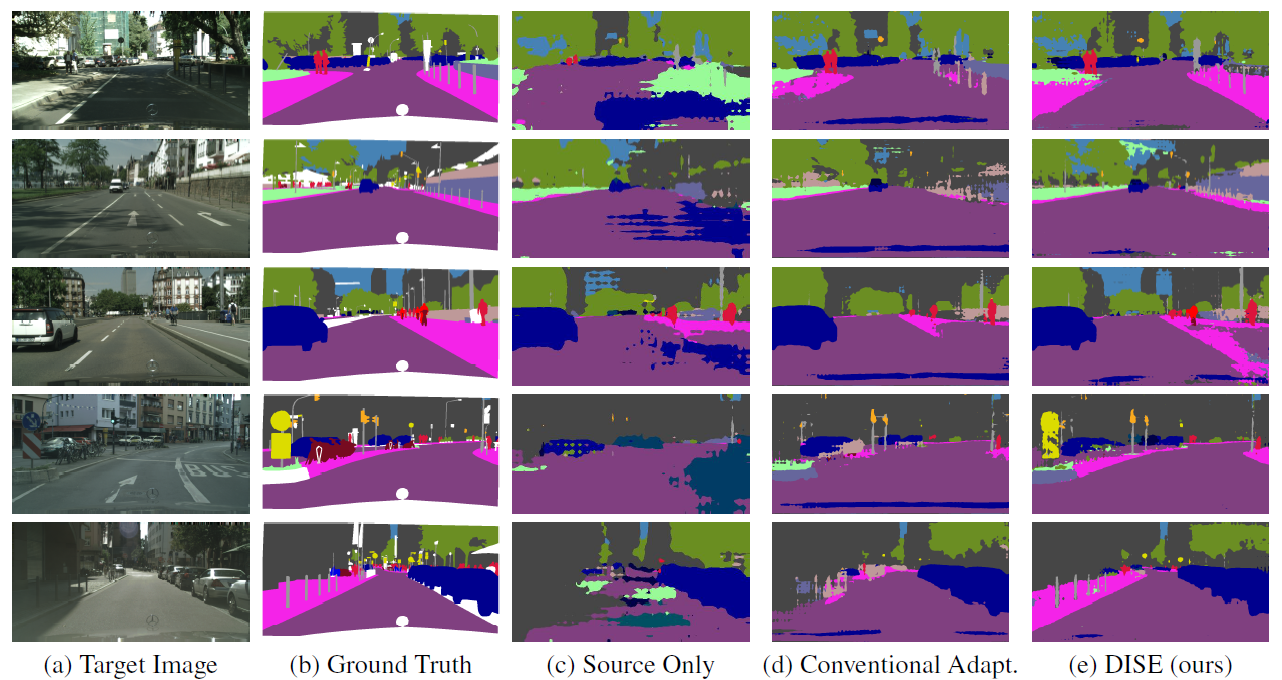
In this paper we tackle the problem of unsupervised domain adaptation for the task of semantic segmentation, where we attempt to transfer the knowledge learned upon synthetic datasets with ground-truth labels to real-world images without any annotation. With the hypothesis that the structural content of images is the most informative and decisive factor to semantic segmentation and can be readily shared across domains, we propose a Domain Invariant Structure Extraction (DISE) framework to disentangle images into domain-invariant structure and domain-specific texture representations, which can further realize image-translation across domains and enable label transfer to improve segmentation performance. Extensive experiments verify the effectiveness of our proposed DISE model and demonstrate its superiority over several state-of-the-art approaches.
PDF Abstract CVPR 2019 PDF CVPR 2019 Abstract





 Cityscapes
Cityscapes
 SYNTHIA
SYNTHIA
 GTA5
GTA5
