All in Tokens: Unifying Output Space of Visual Tasks via Soft Token
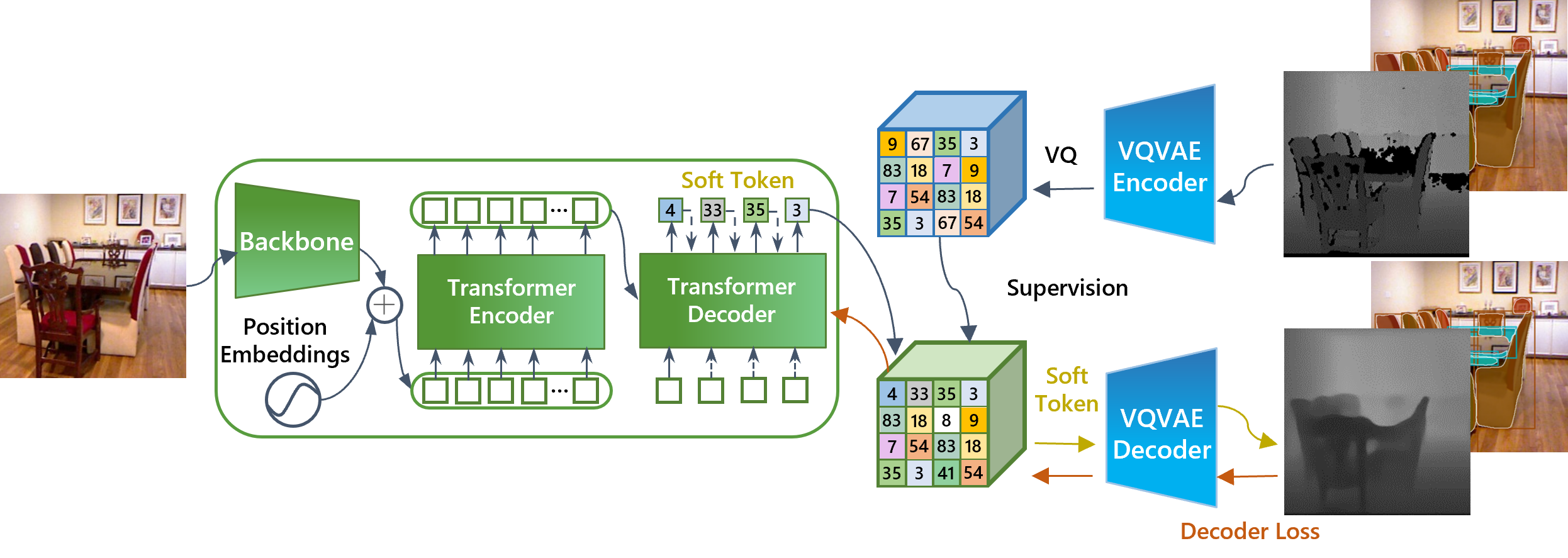
Unlike language tasks, where the output space is usually limited to a set of tokens, the output space of visual tasks is more complicated, making it difficult to build a unified visual model for various visual tasks. In this paper, we seek to unify the output space of visual tasks, so that we can also build a unified model for visual tasks. To this end, we demonstrate a single unified model that simultaneously handles two typical visual tasks of instance segmentation and depth estimation, which have discrete/fixed-length and continuous/varied-length outputs, respectively. We propose several new techniques that take into account the particularity of visual tasks: 1) Soft token. We employ soft token to represent the task output. Unlike hard tokens in the common VQ-VAE which are assigned one-hot to discrete codebooks/vocabularies, the soft token is assigned softly to the codebook embeddings. Soft token can improve the accuracy of both the next token inference and decoding of the task output; 2) Mask augmentation. Many visual tasks have corruption, undefined or invalid values in label annotations, i.e., occluded area of depth maps. We show that a mask augmentation technique can greatly benefit these tasks. With these new techniques and other designs, we show that the proposed general-purpose task-solver can perform both instance segmentation and depth estimation well. Particularly, we achieve 0.279 RMSE on the specific task of NYUv2 depth estimation, setting a new record on this benchmark. The general-purpose task-solver, dubbed AiT, is available at \url{https://github.com/SwinTransformer/AiT}.
PDF Abstract ICCV 2023 PDF ICCV 2023 Abstract




 MS COCO
MS COCO
 NYUv2
NYUv2

