All You Need Is Supervised Learning: From Imitation Learning to Meta-RL With Upside Down RL
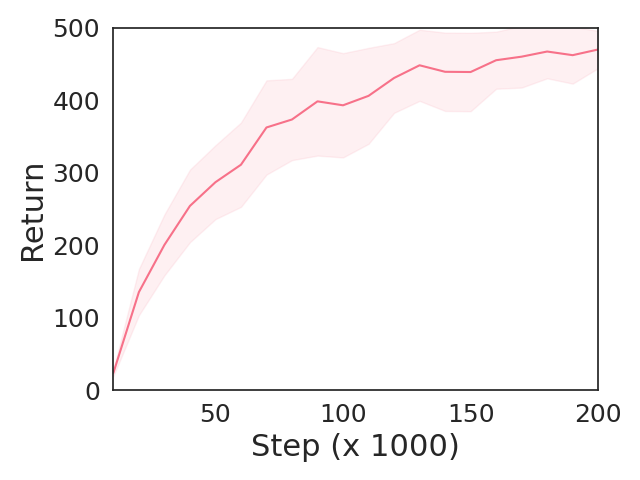
Upside down reinforcement learning (UDRL) flips the conventional use of the return in the objective function in RL upside down, by taking returns as input and predicting actions. UDRL is based purely on supervised learning, and bypasses some prominent issues in RL: bootstrapping, off-policy corrections, and discount factors. While previous work with UDRL demonstrated it in a traditional online RL setting, here we show that this single algorithm can also work in the imitation learning and offline RL settings, be extended to the goal-conditioned RL setting, and even the meta-RL setting. With a general agent architecture, a single UDRL agent can learn across all paradigms.
PDF AbstractCode


Datasets
Add Datasets
introduced or used in this paper
Results from the Paper
Submit
results from this paper
to get state-of-the-art GitHub badges and help the
community compare results to other papers.
Methods
No methods listed for this paper. Add
relevant methods here
