An Annotated Dataset of Coreference in English Literature
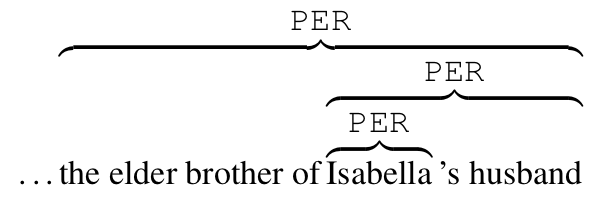
We present in this work a new dataset of coreference annotations for works of literature in English, covering 29,103 mentions in 210,532 tokens from 100 works of fiction. This dataset differs from previous coreference datasets in containing documents whose average length (2,105.3 words) is four times longer than other benchmark datasets (463.7 for OntoNotes), and contains examples of difficult coreference problems common in literature. This dataset allows for an evaluation of cross-domain performance for the task of coreference resolution, and analysis into the characteristics of long-distance within-document coreference.
PDF Abstract LREC 2020 PDF LREC 2020 AbstractCode

 Colab
Colab
Tasks

Datasets
 LitBank
LitBank
 PreCo
PreCo
Results from the Paper
Submit
results from this paper
to get state-of-the-art GitHub badges and help the
community compare results to other papers.
Methods
No methods listed for this paper. Add
relevant methods here
