An Empirical Study of GPT-3 for Few-Shot Knowledge-Based VQA
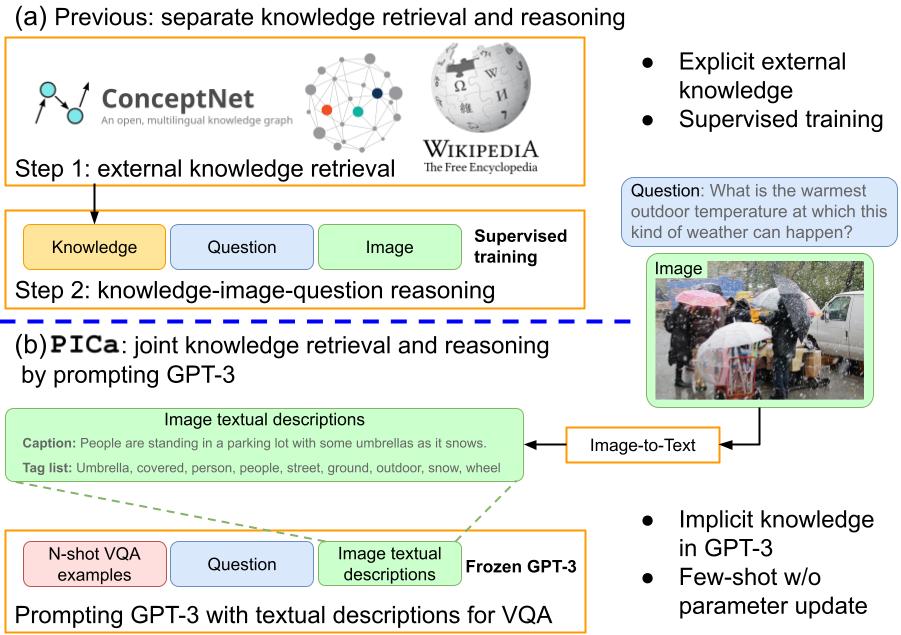
Knowledge-based visual question answering (VQA) involves answering questions that require external knowledge not present in the image. Existing methods first retrieve knowledge from external resources, then reason over the selected knowledge, the input image, and question for answer prediction. However, this two-step approach could lead to mismatches that potentially limit the VQA performance. For example, the retrieved knowledge might be noisy and irrelevant to the question, and the re-embedded knowledge features during reasoning might deviate from their original meanings in the knowledge base (KB). To address this challenge, we propose PICa, a simple yet effective method that Prompts GPT3 via the use of Image Captions, for knowledge-based VQA. Inspired by GPT-3's power in knowledge retrieval and question answering, instead of using structured KBs as in previous work, we treat GPT-3 as an implicit and unstructured KB that can jointly acquire and process relevant knowledge. Specifically, we first convert the image into captions (or tags) that GPT-3 can understand, then adapt GPT-3 to solve the VQA task in a few-shot manner by just providing a few in-context VQA examples. We further boost performance by carefully investigating: (i) what text formats best describe the image content, and (ii) how in-context examples can be better selected and used. PICa unlocks the first use of GPT-3 for multimodal tasks. By using only 16 examples, PICa surpasses the supervised state of the art by an absolute +8.6 points on the OK-VQA dataset. We also benchmark PICa on VQAv2, where PICa also shows a decent few-shot performance.
PDF AbstractCode




Datasets
 MS COCO
MS COCO
 Visual Question Answering
Visual Question Answering
 ConceptNet
ConceptNet
 OK-VQA
OK-VQA
Results from the Paper
 Ranked #20 on
Visual Question Answering (VQA)
on OK-VQA
(using extra training data)
Ranked #20 on
Visual Question Answering (VQA)
on OK-VQA
(using extra training data)
