An empirical study on evaluation metrics of generative adversarial networks
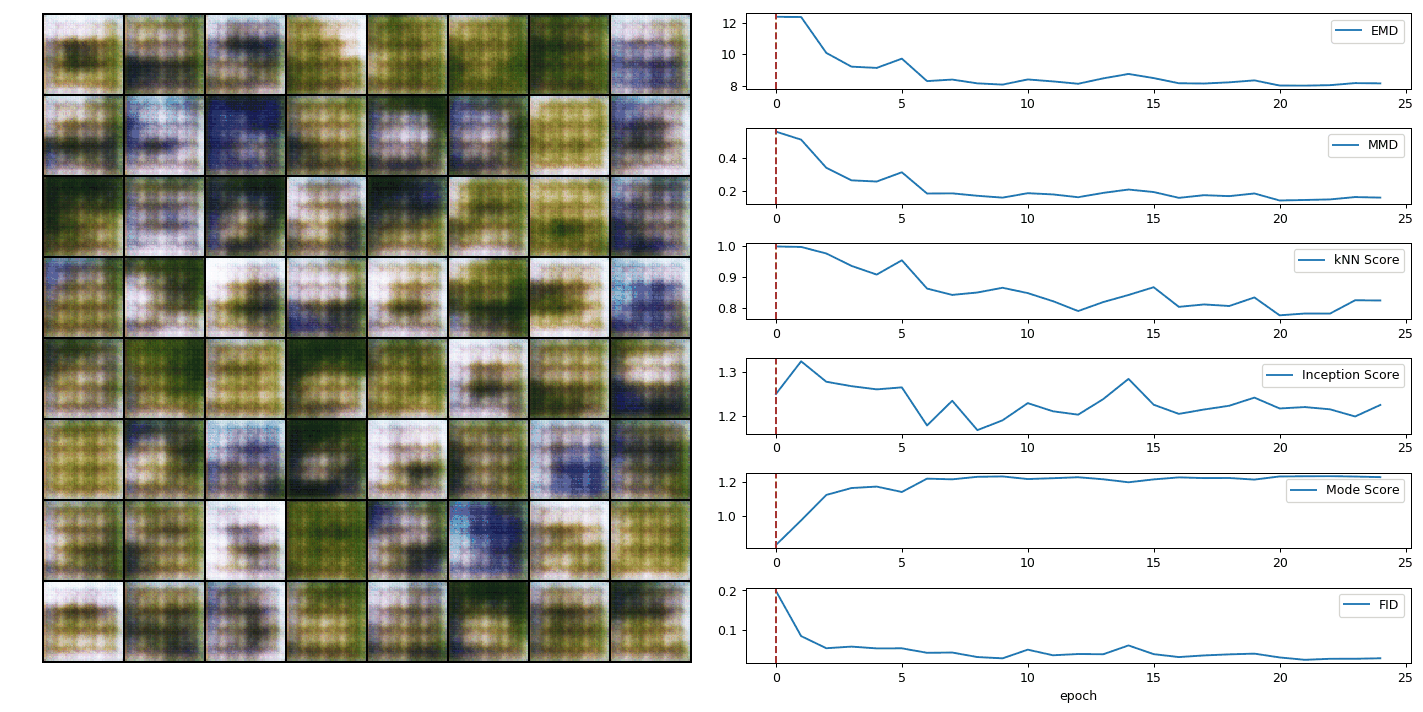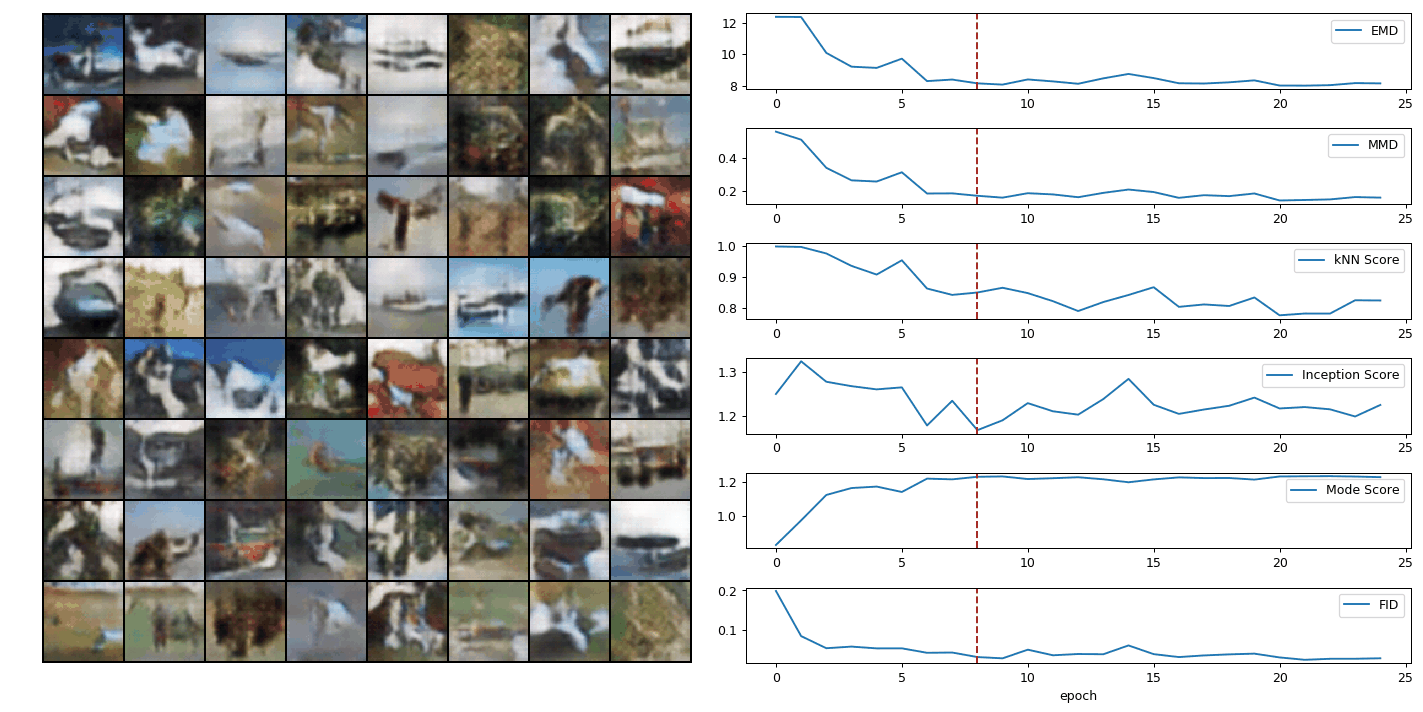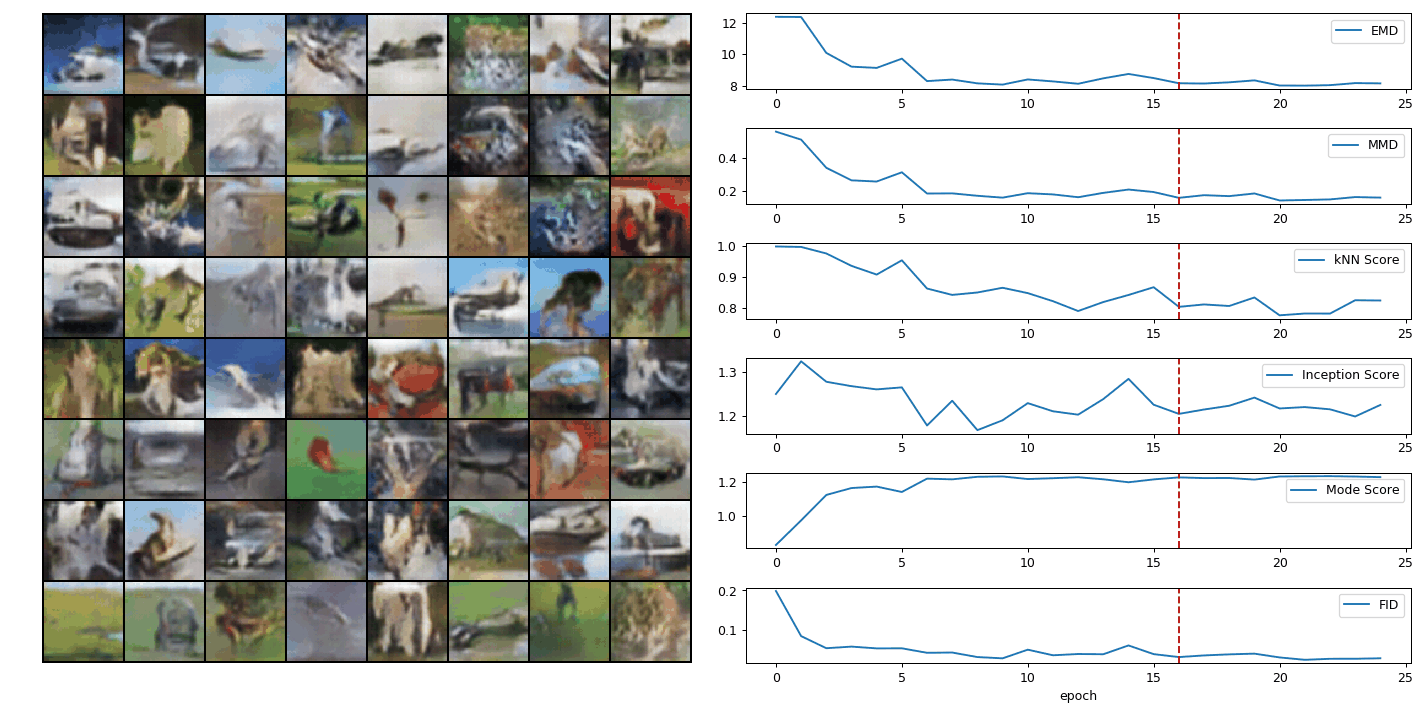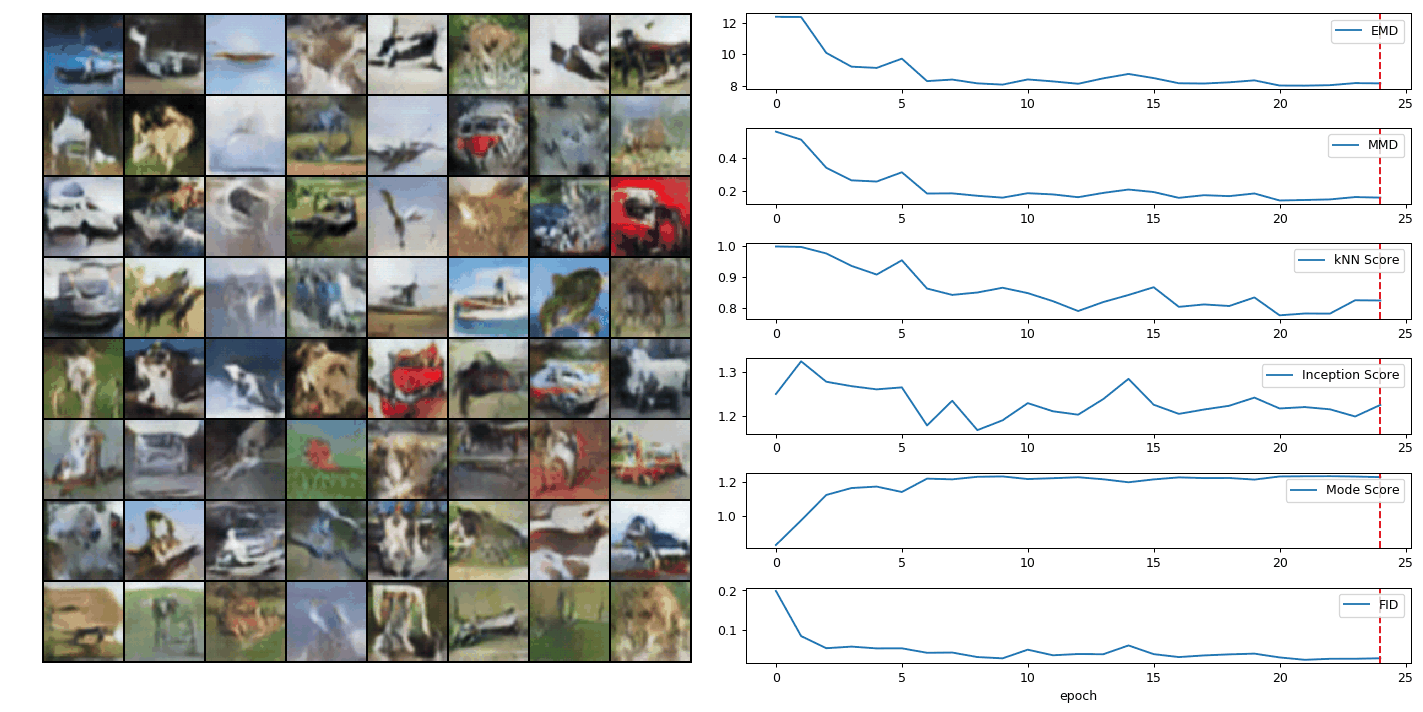
Evaluating generative adversarial networks (GANs) is inherently challenging. In this paper, we revisit several representative sample-based evaluation metrics for GANs, and address the problem of how to evaluate the evaluation metrics. We start with a few necessary conditions for metrics to produce meaningful scores, such as distinguishing real from generated samples, identifying mode dropping and mode collapsing, and detecting overfitting. With a series of carefully designed experiments, we comprehensively investigate existing sample-based metrics and identify their strengths and limitations in practical settings. Based on these results, we observe that kernel Maximum Mean Discrepancy (MMD) and the 1-Nearest-Neighbor (1-NN) two-sample test seem to satisfy most of the desirable properties, provided that the distances between samples are computed in a suitable feature space. Our experiments also unveil interesting properties about the behavior of several popular GAN models, such as whether they are memorizing training samples, and how far they are from learning the target distribution.
PDF Abstract ICLR 2018 PDF ICLR 2018 Abstract
 ImageNet
ImageNet
