Anonymizing Speech with Generative Adversarial Networks to Preserve Speaker Privacy
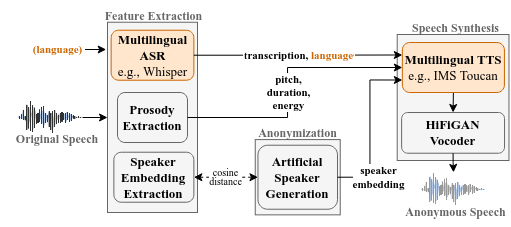
In order to protect the privacy of speech data, speaker anonymization aims for hiding the identity of a speaker by changing the voice in speech recordings. This typically comes with a privacy-utility trade-off between protection of individuals and usability of the data for downstream applications. One of the challenges in this context is to create non-existent voices that sound as natural as possible. In this work, we propose to tackle this issue by generating speaker embeddings using a generative adversarial network with Wasserstein distance as cost function. By incorporating these artificial embeddings into a speech-to-text-to-speech pipeline, we outperform previous approaches in terms of privacy and utility. According to standard objective metrics and human evaluation, our approach generates intelligible and content-preserving yet privacy-protecting versions of the original recordings.
PDF Abstract Spaces
Spaces


 LibriSpeech
LibriSpeech
