Answer Them All! Toward Universal Visual Question Answering Models
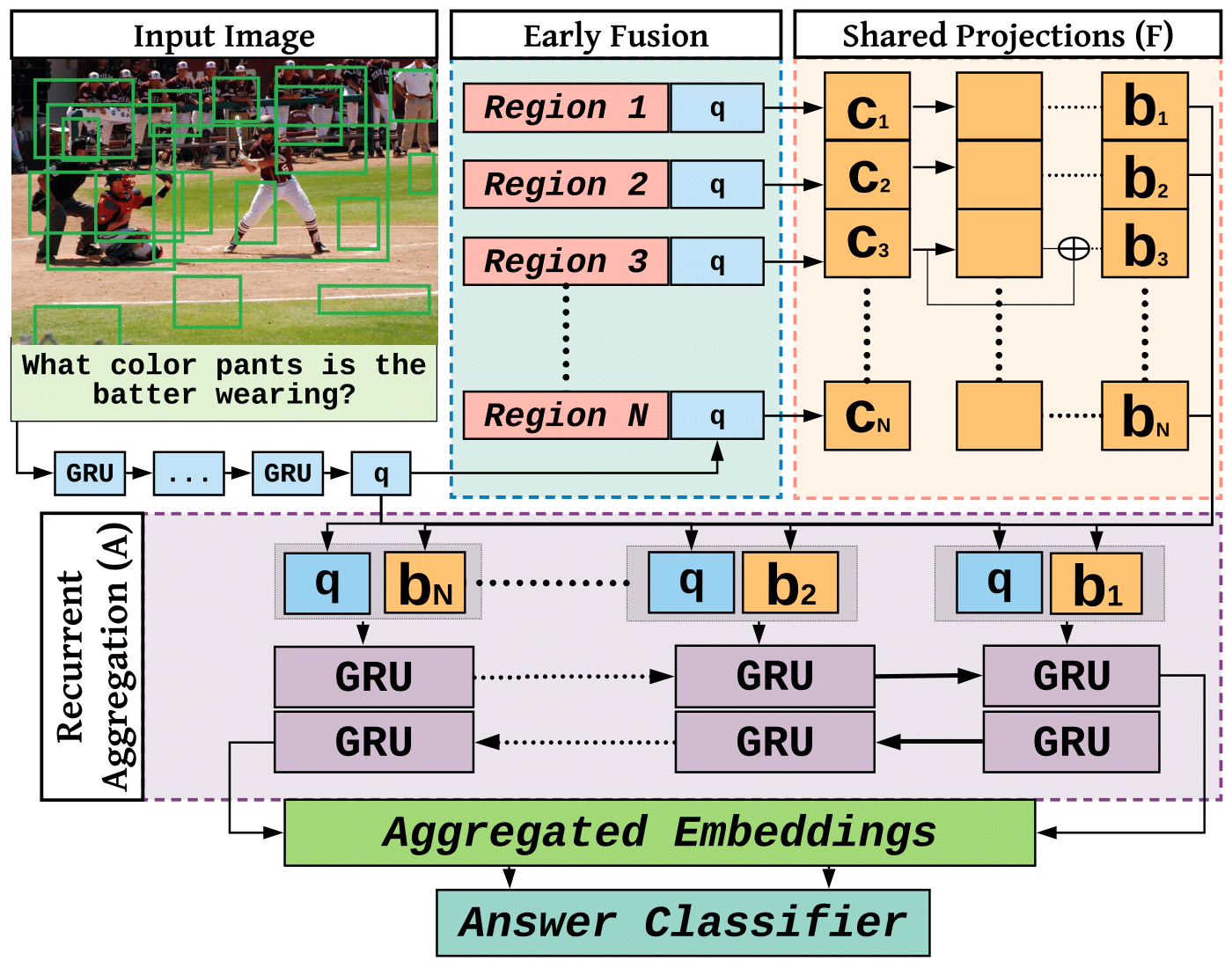
Visual Question Answering (VQA) research is split into two camps: the first focuses on VQA datasets that require natural image understanding and the second focuses on synthetic datasets that test reasoning. A good VQA algorithm should be capable of both, but only a few VQA algorithms are tested in this manner. We compare five state-of-the-art VQA algorithms across eight VQA datasets covering both domains. To make the comparison fair, all of the models are standardized as much as possible, e.g., they use the same visual features, answer vocabularies, etc. We find that methods do not generalize across the two domains. To address this problem, we propose a new VQA algorithm that rivals or exceeds the state-of-the-art for both domains.
PDF Abstract CVPR 2019 PDF CVPR 2019 Abstract



 Visual Question Answering
Visual Question Answering
 Visual Genome
Visual Genome
 CLEVR
CLEVR
 SHAPES
SHAPES
 TDIUC
TDIUC
