APEACH: Attacking Pejorative Expressions with Analysis on Crowd-Generated Hate Speech Evaluation Datasets
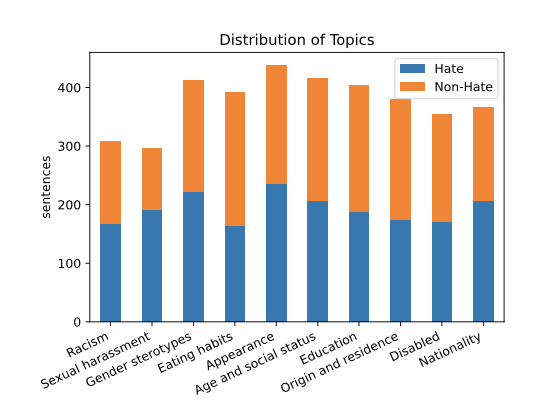
In hate speech detection, developing training and evaluation datasets across various domains is the critical issue. Whereas, major approaches crawl social media texts and hire crowd-workers to annotate the data. Following this convention often restricts the scope of pejorative expressions to a single domain lacking generalization. Sometimes domain overlap between training corpus and evaluation set overestimate the prediction performance when pretraining language models on low-data language. To alleviate these problems in Korean, we propose APEACH that asks unspecified users to generate hate speech examples followed by minimal post-labeling. We find that APEACH can collect useful datasets that are less sensitive to the lexical overlaps between the pretraining corpus and the evaluation set, thereby properly measuring the model performance.
PDF AbstractCode
 Colab
Colab
Tasks

Datasets
Introduced in the Paper:
Korean Hate Speech Evaluation DatasetsUsed in the Paper:
Korean HateSpeech Dataset