Application of Self-Play Reinforcement Learning to a Four-Player Game of Imperfect Information
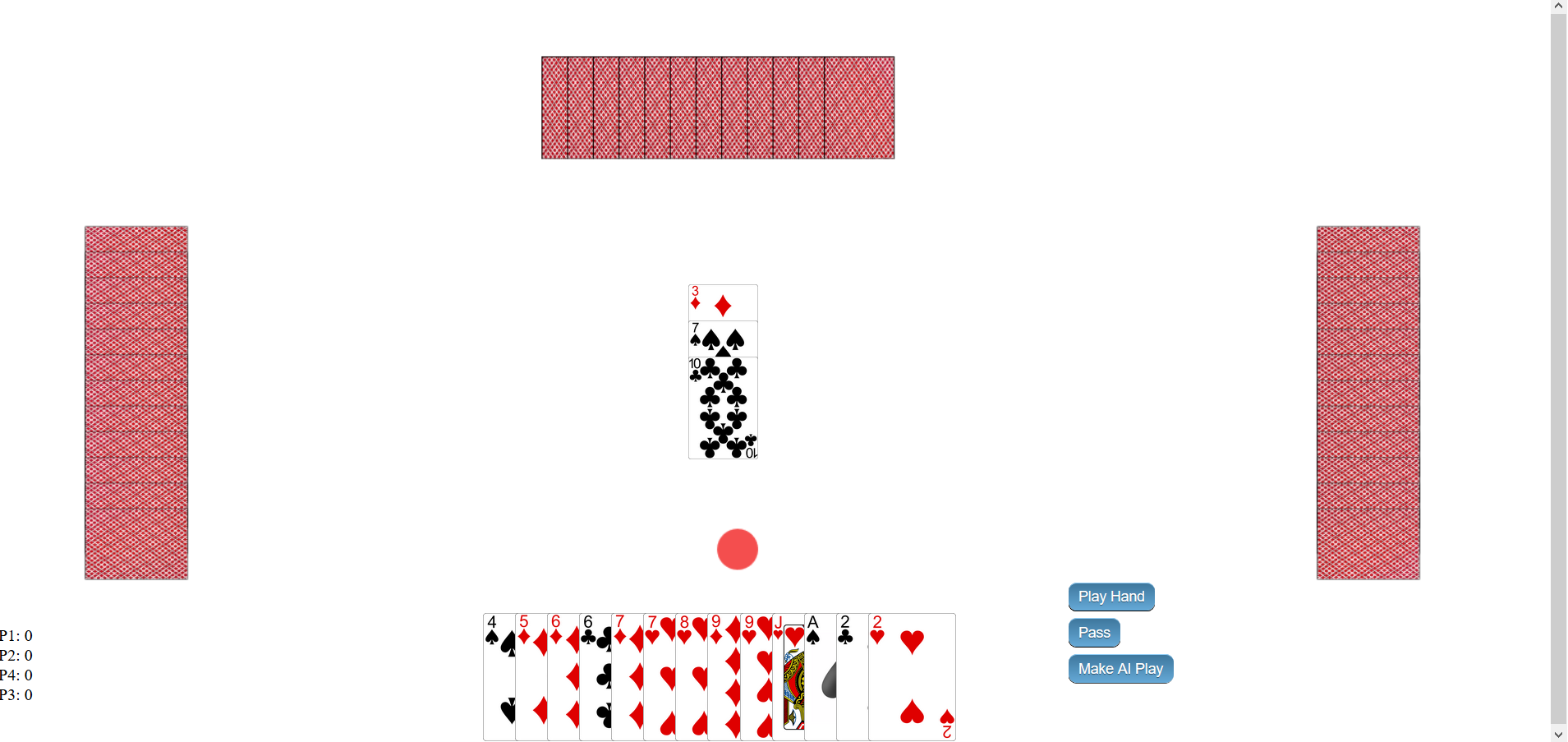
We introduce a new virtual environment for simulating a card game known as "Big 2". This is a four-player game of imperfect information with a relatively complicated action space (being allowed to play 1,2,3,4 or 5 card combinations from an initial starting hand of 13 cards). As such it poses a challenge for many current reinforcement learning methods. We then use the recently proposed "Proximal Policy Optimization" algorithm to train a deep neural network to play the game, purely learning via self-play, and find that it is able to reach a level which outperforms amateur human players after only a relatively short amount of training time and without needing to search a tree of future game states.
PDF Abstract


Datasets
Add Datasets
introduced or used in this paper
Results from the Paper
Submit
results from this paper
to get state-of-the-art GitHub badges and help the
community compare results to other papers.
Methods
No methods listed for this paper. Add
relevant methods here
