Approximating Gradients for Differentiable Quality Diversity in Reinforcement Learning
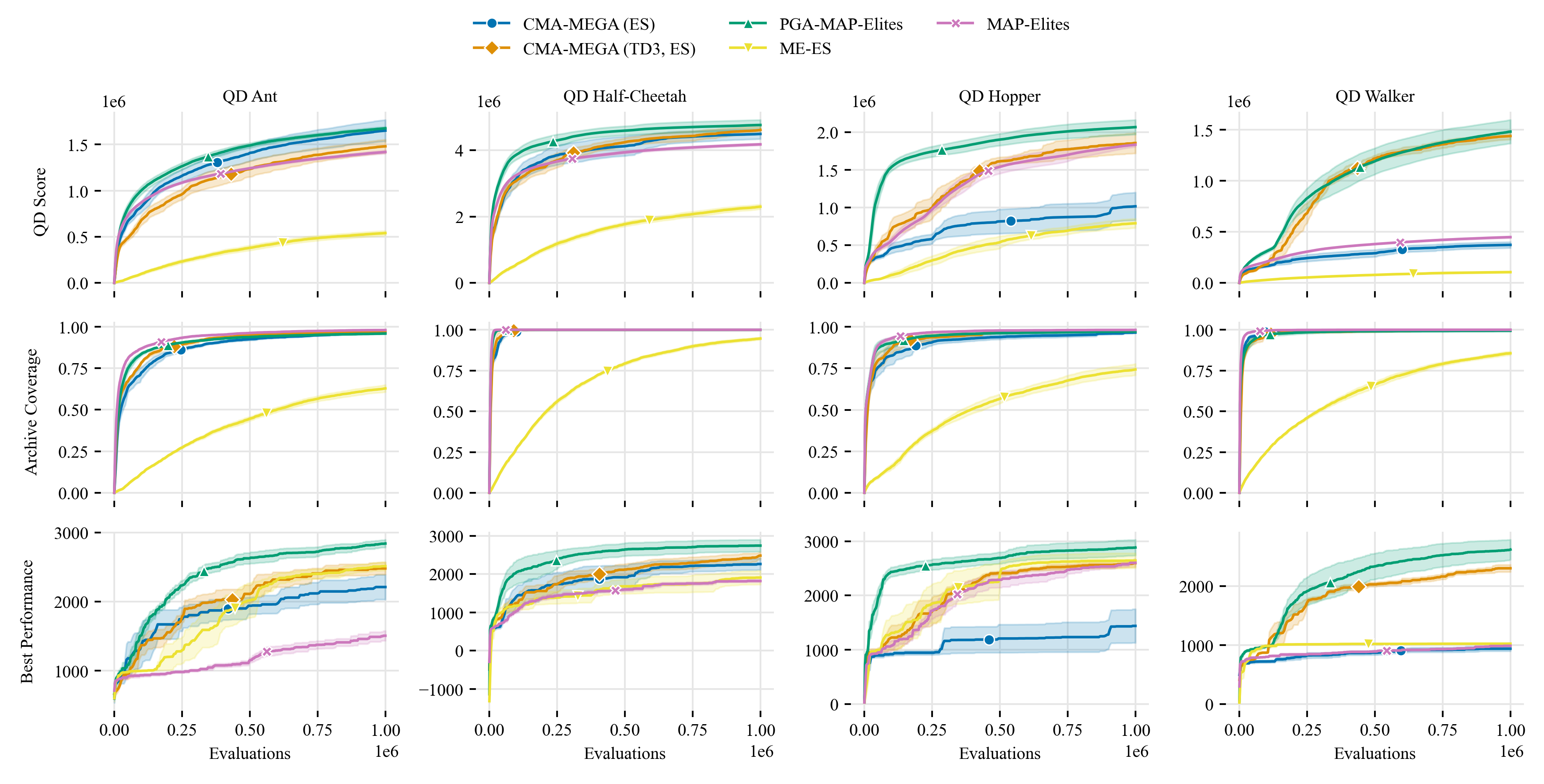
Consider the problem of training robustly capable agents. One approach is to generate a diverse collection of agent polices. Training can then be viewed as a quality diversity (QD) optimization problem, where we search for a collection of performant policies that are diverse with respect to quantified behavior. Recent work shows that differentiable quality diversity (DQD) algorithms greatly accelerate QD optimization when exact gradients are available. However, agent policies typically assume that the environment is not differentiable. To apply DQD algorithms to training agent policies, we must approximate gradients for performance and behavior. We propose two variants of the current state-of-the-art DQD algorithm that compute gradients via approximation methods common in reinforcement learning (RL). We evaluate our approach on four simulated locomotion tasks. One variant achieves results comparable to the current state-of-the-art in combining QD and RL, while the other performs comparably in two locomotion tasks. These results provide insight into the limitations of current DQD algorithms in domains where gradients must be approximated. Source code is available at https://github.com/icaros-usc/dqd-rl
PDF Abstract

