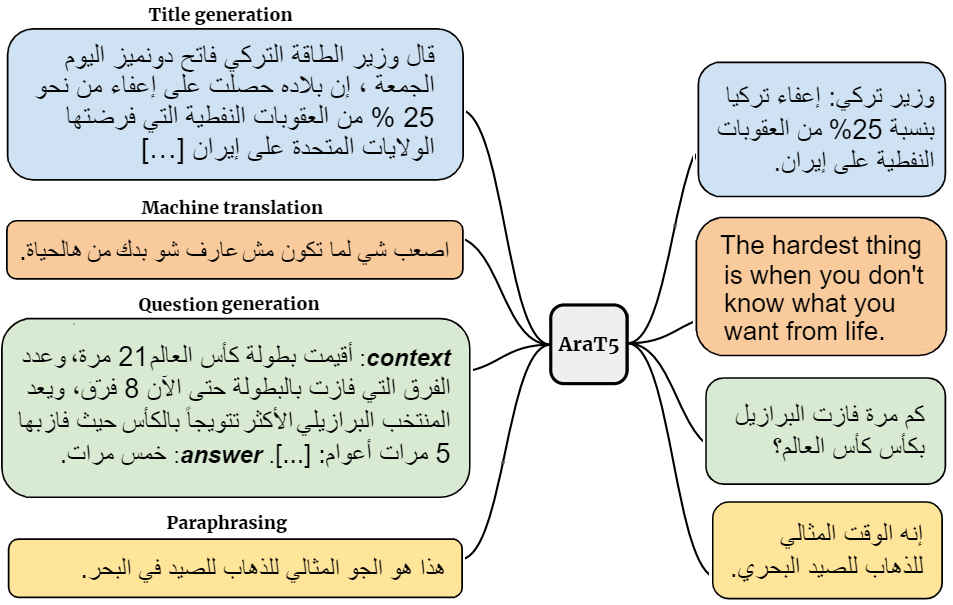
AraT5: Text-to-Text Transformers for Arabic Language Generation
Transfer learning with a unified Transformer framework (T5) that converts all language problems into a text-to-text format was recently proposed as a simple and effective transfer learning approach. Although a multilingual version of the T5 model (mT5) was also introduced, it is not clear how well it can fare on non-English tasks involving diverse data. To investigate this question, we apply mT5 on a language with a wide variety of dialects--Arabic. For evaluation, we introduce a novel benchmark for ARabic language GENeration (ARGEN), covering seven important tasks. For model comparison, we pre-train three powerful Arabic T5-style models and evaluate them on ARGEN. Although pre-trained with ~49 less data, our new models perform significantly better than mT5 on all ARGEN tasks (in 52 out of 59 test sets) and set several new SOTAs. Our models also establish new SOTA on the recently-proposed, large Arabic language understanding evaluation benchmark ARLUE (Abdul-Mageed et al., 2021). Our new models are publicly available. We also link to ARGEN datasets through our repository: https://github.com/UBC-NLP/araT5.
PDF Abstract ACL 2022 PDF ACL 2022 Abstract


 C4
C4
