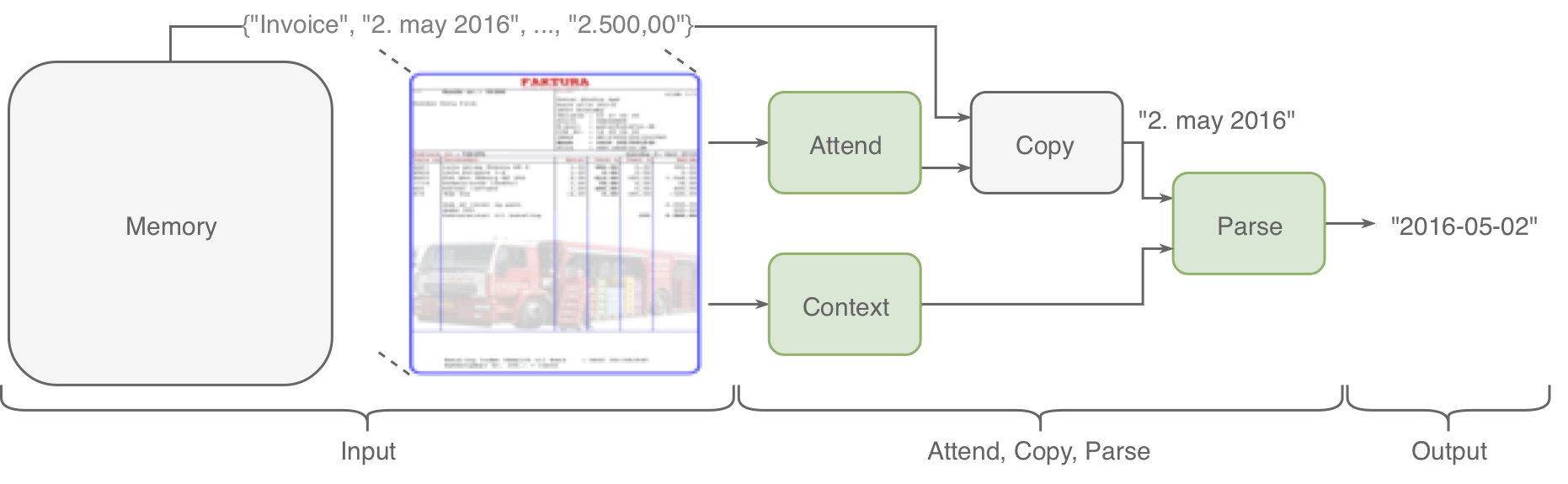
Attend, Copy, Parse -- End-to-end information extraction from documents
Document information extraction tasks performed by humans create data consisting of a PDF or document image input, and extracted string outputs. This end-to-end data is naturally consumed and produced when performing the task because it is valuable in and of itself. It is naturally available, at no additional cost. Unfortunately, state-of-the-art word classification methods for information extraction cannot use this data, instead requiring word-level labels which are expensive to create and consequently not available for many real life tasks. In this paper we propose the Attend, Copy, Parse architecture, a deep neural network model that can be trained directly on end-to-end data, bypassing the need for word-level labels. We evaluate the proposed architecture on a large diverse set of invoices, and outperform a state-of-the-art production system based on word classification. We believe our proposed architecture can be used on many real life information extraction tasks where word classification cannot be used due to a lack of the required word-level labels.
PDF Abstract


