Attention Consistency on Visual Corruptions for Single-Source Domain Generalization
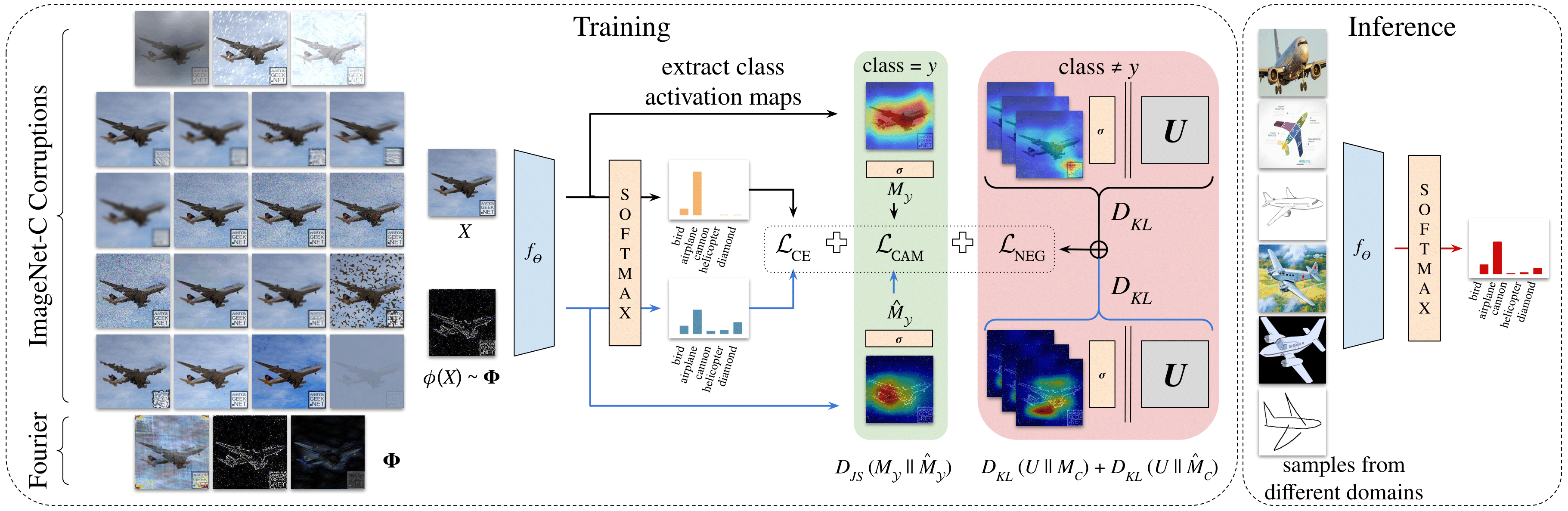
Generalizing visual recognition models trained on a single distribution to unseen input distributions (i.e. domains) requires making them robust to superfluous correlations in the training set. In this work, we achieve this goal by altering the training images to simulate new domains and imposing consistent visual attention across the different views of the same sample. We discover that the first objective can be simply and effectively met through visual corruptions. Specifically, we alter the content of the training images using the nineteen corruptions of the ImageNet-C benchmark and three additional transformations based on Fourier transform. Since these corruptions preserve object locations, we propose an attention consistency loss to ensure that class activation maps across original and corrupted versions of the same training sample are aligned. We name our model Attention Consistency on Visual Corruptions (ACVC). We show that ACVC consistently achieves the state of the art on three single-source domain generalization benchmarks, PACS, COCO, and the large-scale DomainNet.
PDF Abstract

 MS COCO
MS COCO
 DomainNet
DomainNet
 PACS
PACS
 ImageNet-C
ImageNet-C
