AudioEar: Single-View Ear Reconstruction for Personalized Spatial Audio
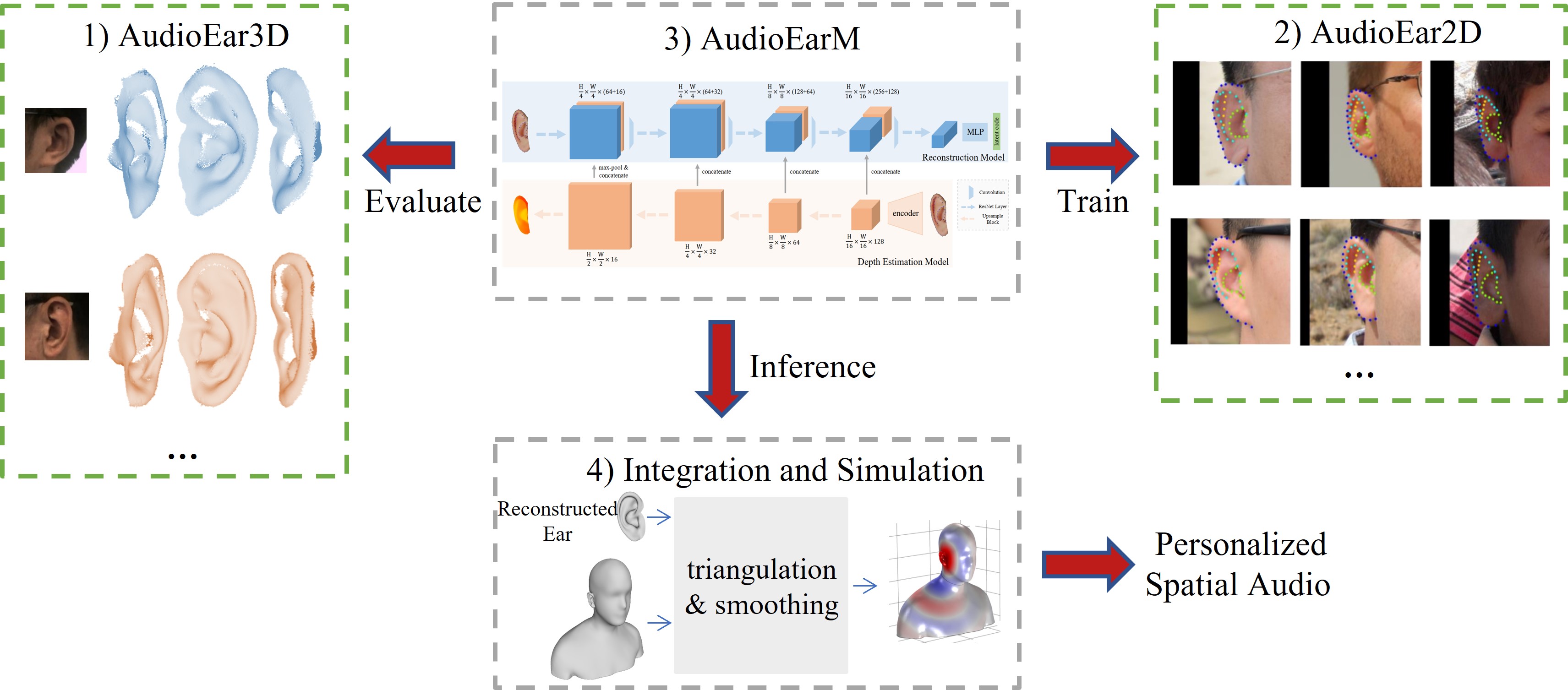
Spatial audio, which focuses on immersive 3D sound rendering, is widely applied in the acoustic industry. One of the key problems of current spatial audio rendering methods is the lack of personalization based on different anatomies of individuals, which is essential to produce accurate sound source positions. In this work, we address this problem from an interdisciplinary perspective. The rendering of spatial audio is strongly correlated with the 3D shape of human bodies, particularly ears. To this end, we propose to achieve personalized spatial audio by reconstructing 3D human ears with single-view images. First, to benchmark the ear reconstruction task, we introduce AudioEar3D, a high-quality 3D ear dataset consisting of 112 point cloud ear scans with RGB images. To self-supervisedly train a reconstruction model, we further collect a 2D ear dataset composed of 2,000 images, each one with manual annotation of occlusion and 55 landmarks, named AudioEar2D. To our knowledge, both datasets have the largest scale and best quality of their kinds for public use. Further, we propose AudioEarM, a reconstruction method guided by a depth estimation network that is trained on synthetic data, with two loss functions tailored for ear data. Lastly, to fill the gap between the vision and acoustics community, we develop a pipeline to integrate the reconstructed ear mesh with an off-the-shelf 3D human body and simulate a personalized Head-Related Transfer Function (HRTF), which is the core of spatial audio rendering. Code and data are publicly available at https://github.com/seanywang0408/AudioEar.
PDF Abstract

 FFHQ
FFHQ
