MiniDisc: Minimal Distillation Schedule for Language Model Compression
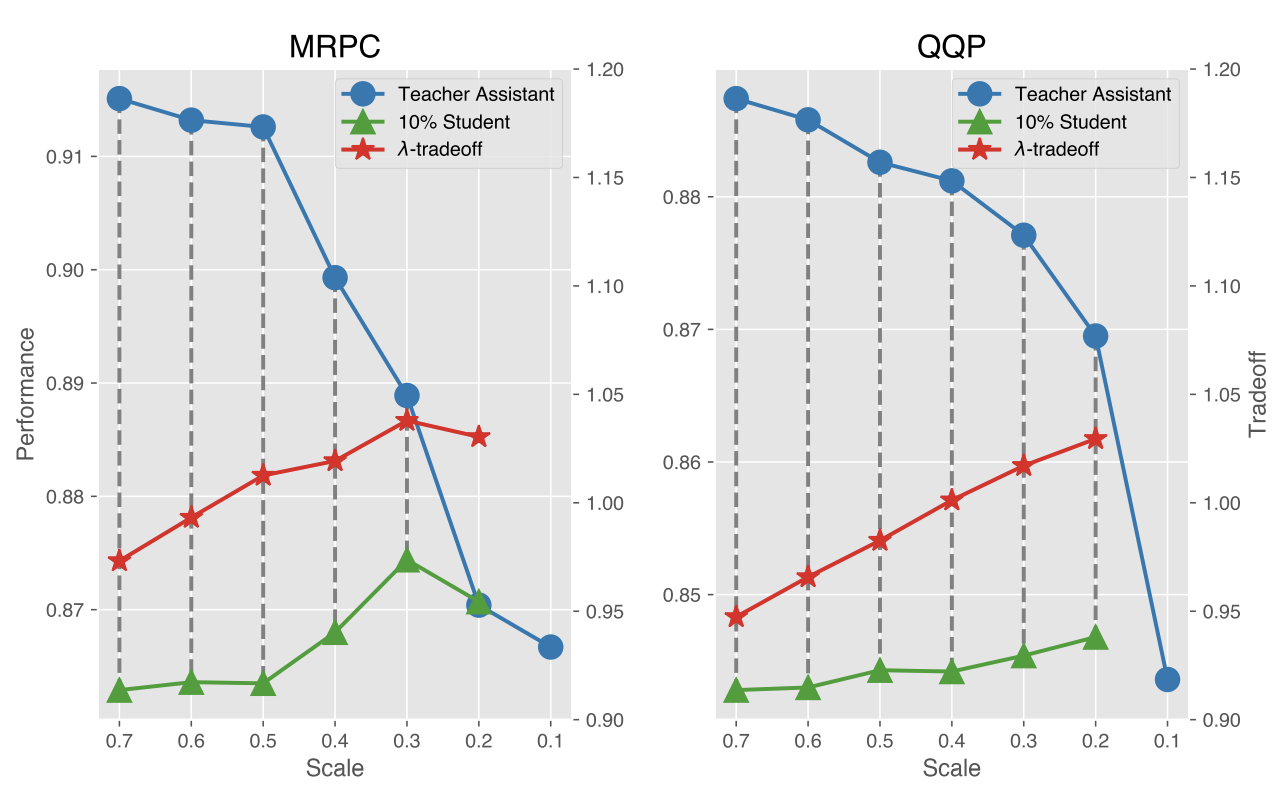
Recent studies have uncovered that language model distillation is less effective when facing a large capacity gap between the teacher and the student, and introduced teacher assistant-based distillation to bridge the gap. As a connection, the scale and the performance of the teacher assistant is of vital importance to bring the knowledge from the teacher to the student. However, existing teacher assistant-based methods require maximally many trials before scheduling an optimal teacher assistant. To this end, we propose a minimal distillation schedule (MiniDisc) for scheduling the optimal teacher assistant in minimally one trial. In particular, motivated by the finding that the performance of the student is positively correlated to the scale-performance tradeoff of the teacher assistant, MiniDisc is designed with a $\lambda$-tradeoff to measure the optimality of the teacher assistant without trial distillation to the student. MiniDisc then can schedule the optimal teacher assistant with the best $\lambda$-tradeoff in a sandwich framework. MiniDisc is evaluated with an extensive set of experiments on GLUE. Experimental results demonstrate the improved efficiency our MiniDisc compared to several state-of-the-art baselines. We further apply MiniDisc to a language model with billions of parameters and show its scalability.
PDF Abstract


 GLUE
GLUE
 SST
SST
 QNLI
QNLI
 MRPC
MRPC
 CoLA
CoLA
