Autoencoders as Cross-Modal Teachers: Can Pretrained 2D Image Transformers Help 3D Representation Learning?
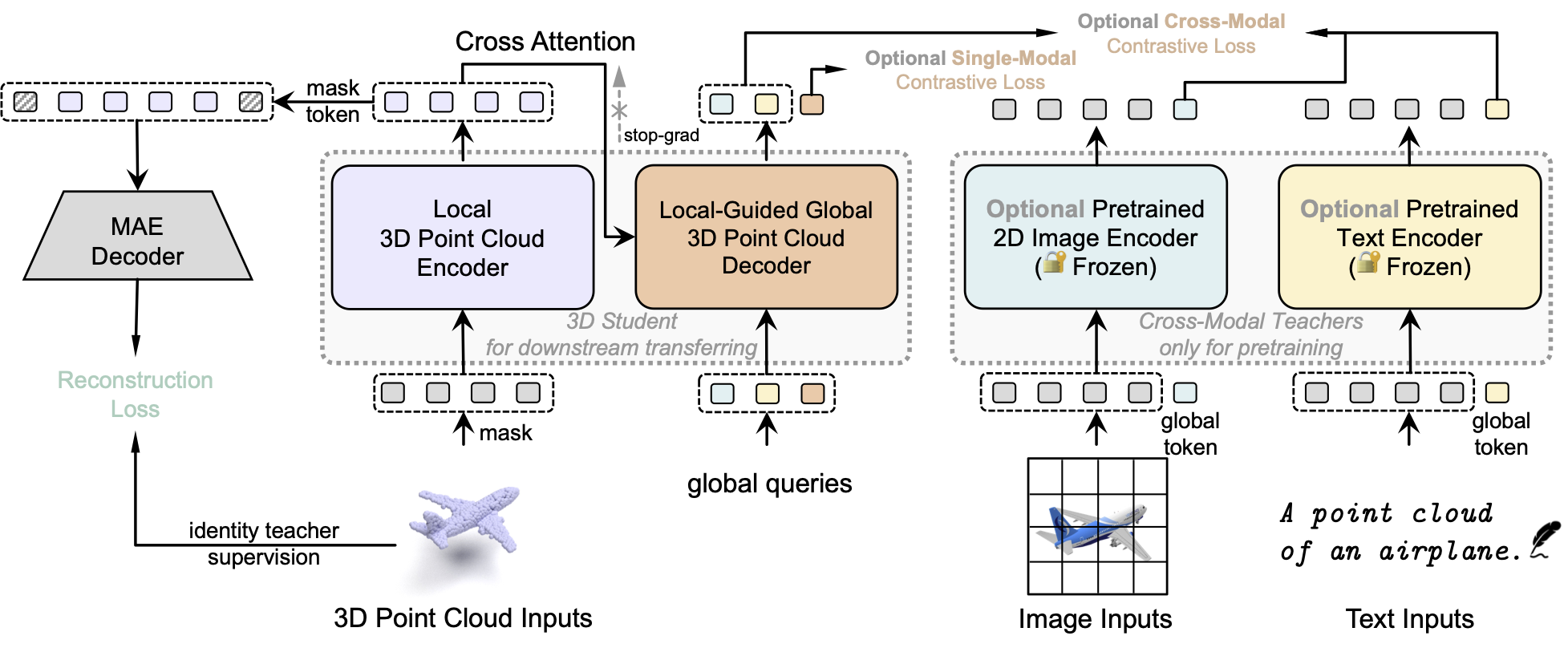
The success of deep learning heavily relies on large-scale data with comprehensive labels, which is more expensive and time-consuming to fetch in 3D compared to 2D images or natural languages. This promotes the potential of utilizing models pretrained with data more than 3D as teachers for cross-modal knowledge transferring. In this paper, we revisit masked modeling in a unified fashion of knowledge distillation, and we show that foundational Transformers pretrained with 2D images or natural languages can help self-supervised 3D representation learning through training Autoencoders as Cross-Modal Teachers (ACT). The pretrained Transformers are transferred as cross-modal 3D teachers using discrete variational autoencoding self-supervision, during which the Transformers are frozen with prompt tuning for better knowledge inheritance. The latent features encoded by the 3D teachers are used as the target of masked point modeling, wherein the dark knowledge is distilled to the 3D Transformer students as foundational geometry understanding. Our ACT pretrained 3D learner achieves state-of-the-art generalization capacity across various downstream benchmarks, e.g., 88.21% overall accuracy on ScanObjectNN. Codes have been released at https://github.com/RunpeiDong/ACT.
PDF AbstractCode




Datasets
 ShapeNet
ShapeNet
 ModelNet
ModelNet
 ScanNet
ScanNet
 S3DIS
S3DIS
 ScanObjectNN
ScanObjectNN
Results from the Paper
 Ranked #5 on
Few-Shot 3D Point Cloud Classification
on ModelNet40 10-way (10-shot)
(using extra training data)
Ranked #5 on
Few-Shot 3D Point Cloud Classification
on ModelNet40 10-way (10-shot)
(using extra training data)
