Back to the Future: Joint Aware Temporal Deep Learning 3D Human Pose Estimation
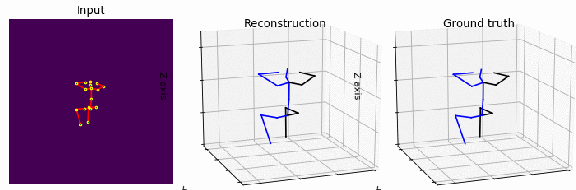
We propose a new deep learning network that introduces a deeper CNN channel filter and constraints as losses to reduce joint position and motion errors for 3D video human body pose estimation. Our model outperforms the previous best result from the literature based on mean per-joint position error, velocity error, and acceleration errors on the Human 3.6M benchmark corresponding to a new state-of-the-art mean error reduction in all protocols and motion metrics. Mean per joint error is reduced by 1%, velocity error by 7% and acceleration by 13% compared to the best results from the literature. Our contribution increasing positional accuracy and motion smoothness in video can be integrated with future end to end networks without increasing network complexity. Our model and code are available at https://vnmr.github.io/ Keywords: 3D, human, image, pose, action, detection, object, video, visual, supervised, joint, kinematic
PDF Abstract




 Human3.6M
Human3.6M

