Behind the Scenes: Density Fields for Single View Reconstruction
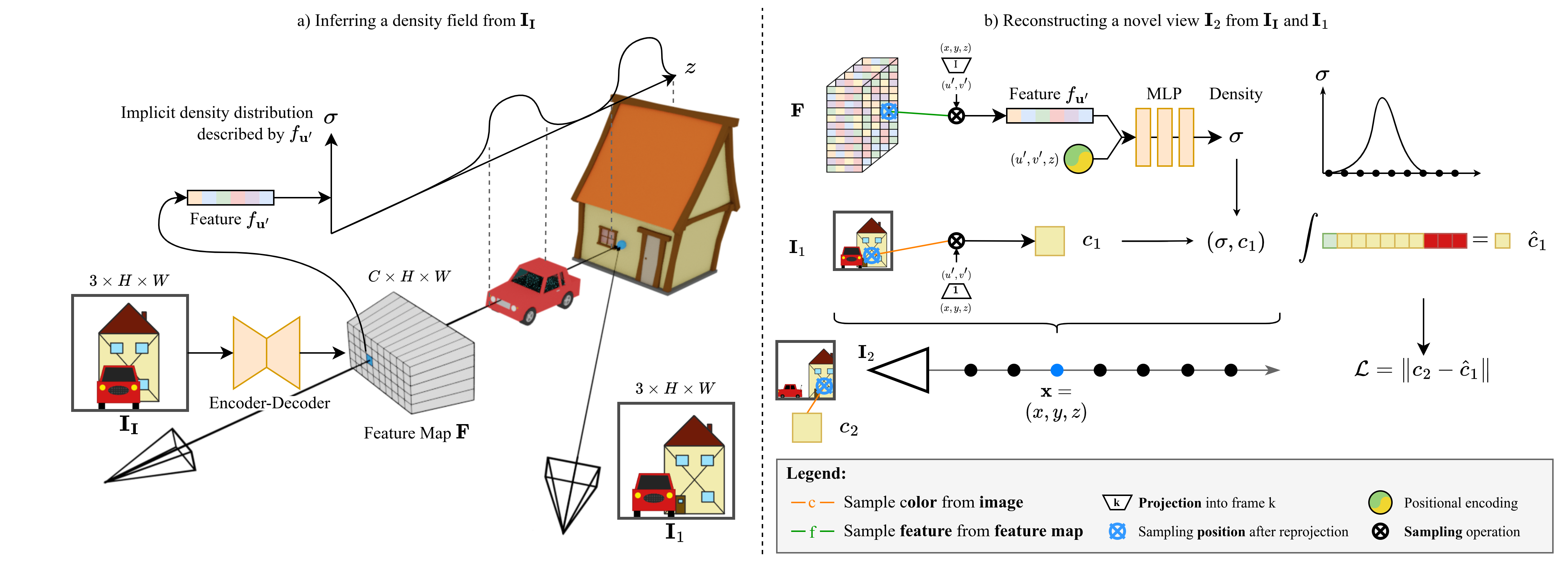
Inferring a meaningful geometric scene representation from a single image is a fundamental problem in computer vision. Approaches based on traditional depth map prediction can only reason about areas that are visible in the image. Currently, neural radiance fields (NeRFs) can capture true 3D including color, but are too complex to be generated from a single image. As an alternative, we propose to predict implicit density fields. A density field maps every location in the frustum of the input image to volumetric density. By directly sampling color from the available views instead of storing color in the density field, our scene representation becomes significantly less complex compared to NeRFs, and a neural network can predict it in a single forward pass. The prediction network is trained through self-supervision from only video data. Our formulation allows volume rendering to perform both depth prediction and novel view synthesis. Through experiments, we show that our method is able to predict meaningful geometry for regions that are occluded in the input image. Additionally, we demonstrate the potential of our approach on three datasets for depth prediction and novel-view synthesis.
PDF Abstract CVPR 2023 PDF CVPR 2023 Abstract



 KITTI
KITTI
 KITTI-360
KITTI-360
 RealEstate10K
RealEstate10K
