BEVT: BERT Pretraining of Video Transformers
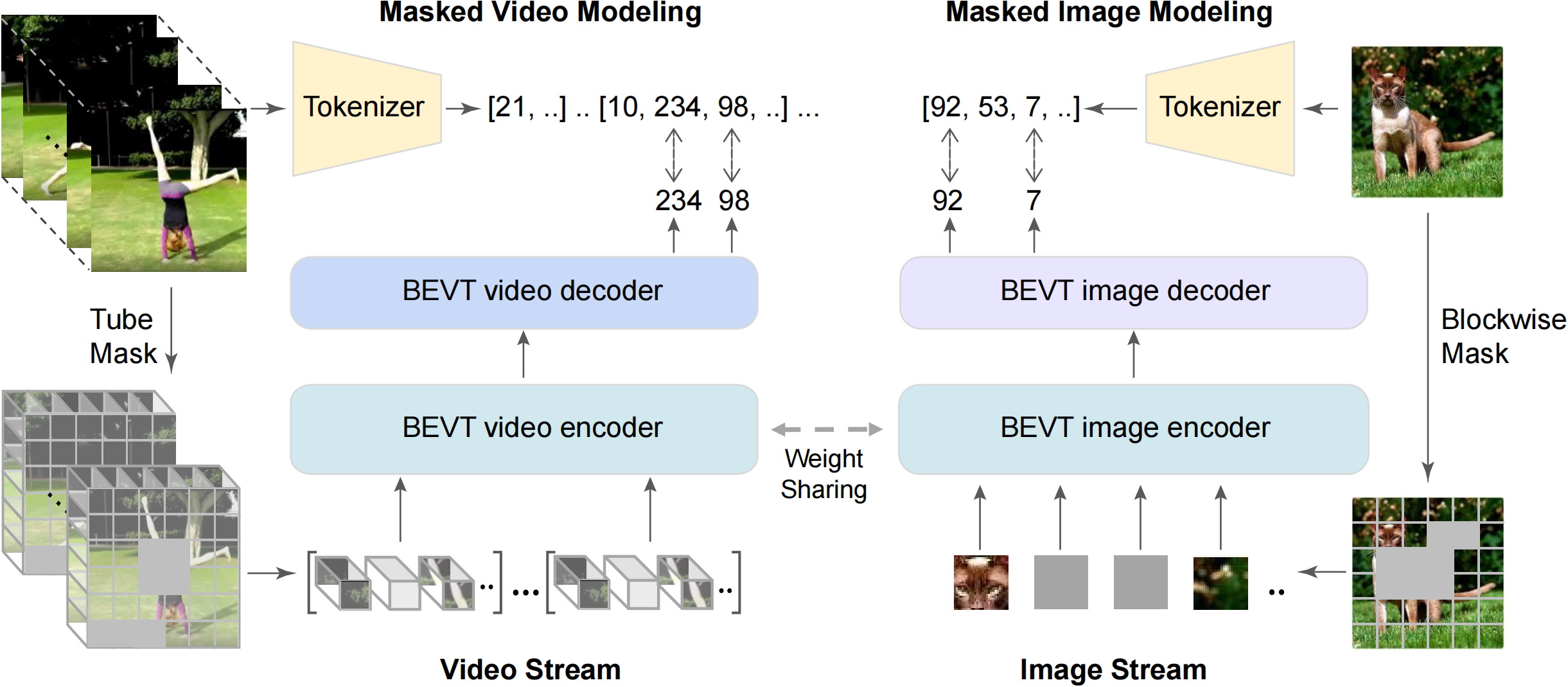
This paper studies the BERT pretraining of video transformers. It is a straightforward but worth-studying extension given the recent success from BERT pretraining of image transformers. We introduce BEVT which decouples video representation learning into spatial representation learning and temporal dynamics learning. In particular, BEVT first performs masked image modeling on image data, and then conducts masked image modeling jointly with masked video modeling on video data. This design is motivated by two observations: 1) transformers learned on image datasets provide decent spatial priors that can ease the learning of video transformers, which are often times computationally-intensive if trained from scratch; 2) discriminative clues, i.e., spatial and temporal information, needed to make correct predictions vary among different videos due to large intra-class and inter-class variations. We conduct extensive experiments on three challenging video benchmarks where BEVT achieves very promising results. On Kinetics 400, for which recognition mostly relies on discriminative spatial representations, BEVT achieves comparable results to strong supervised baselines. On Something-Something-V2 and Diving 48, which contain videos relying on temporal dynamics, BEVT outperforms by clear margins all alternative baselines and achieves state-of-the-art performance with a 71.4\% and 87.2\% Top-1 accuracy respectively. Code will be made available at \url{https://github.com/xyzforever/BEVT}.
PDF Abstract CVPR 2022 PDF CVPR 2022 AbstractCode



Datasets
 Something-Something V2
Something-Something V2
 HowTo100M
HowTo100M

| Task | Dataset | Model | Metric Name | Metric Value | Global Rank | Uses Extra Training Data |
Benchmark |
|---|---|---|---|---|---|---|---|
| Action Recognition | Diving-48 | BEVT | Accuracy | 86.7 | # 8 | ||
| Action Recognition | Something-Something V2 | BEVT (IN-1K + Kinetics400 pretrain) | Top-1 Accuracy | 71.4 | # 28 | ||
| Top-5 Accuracy | - | # 86 | |||||
| Parameters | 89 | # 23 | |||||
| GFLOPs | 321x3 | # 6 |
