Beyond Masking: Demystifying Token-Based Pre-Training for Vision Transformers
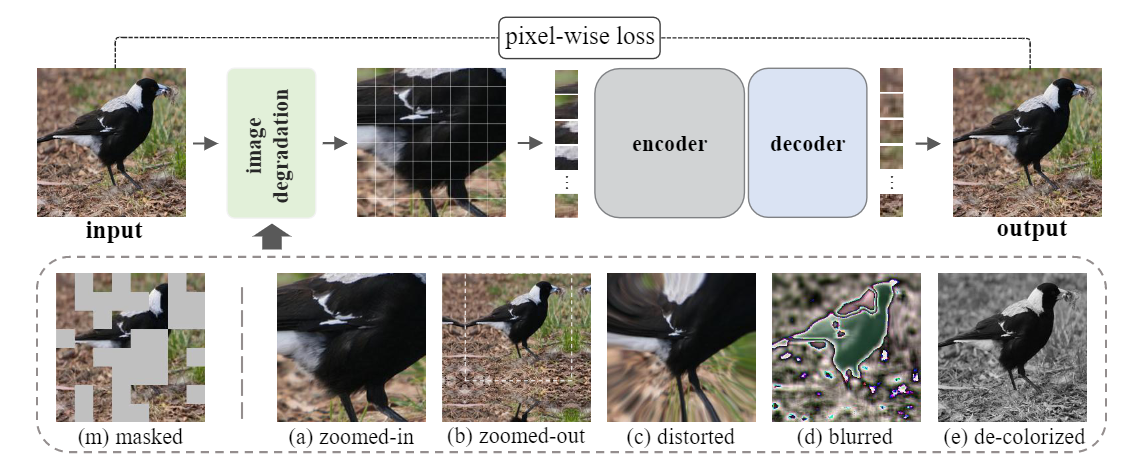
The past year has witnessed a rapid development of masked image modeling (MIM). MIM is mostly built upon the vision transformers, which suggests that self-supervised visual representations can be done by masking input image parts while requiring the target model to recover the missing contents. MIM has demonstrated promising results on downstream tasks, yet we are interested in whether there exist other effective ways to `learn by recovering missing contents'. In this paper, we investigate this topic by designing five other learning objectives that follow the same procedure as MIM but degrade the input image in different ways. With extensive experiments, we manage to summarize a few design principles for token-based pre-training of vision transformers. In particular, the best practice is obtained by keeping the original image style and enriching spatial masking with spatial misalignment -- this design achieves superior performance over MIM in a series of downstream recognition tasks without extra computational cost. The code is available at https://github.com/sunsmarterjie/beyond_masking.
PDF Abstract
 MS COCO
MS COCO
