BiFuse++: Self-supervised and Efficient Bi-projection Fusion for 360 Depth Estimation
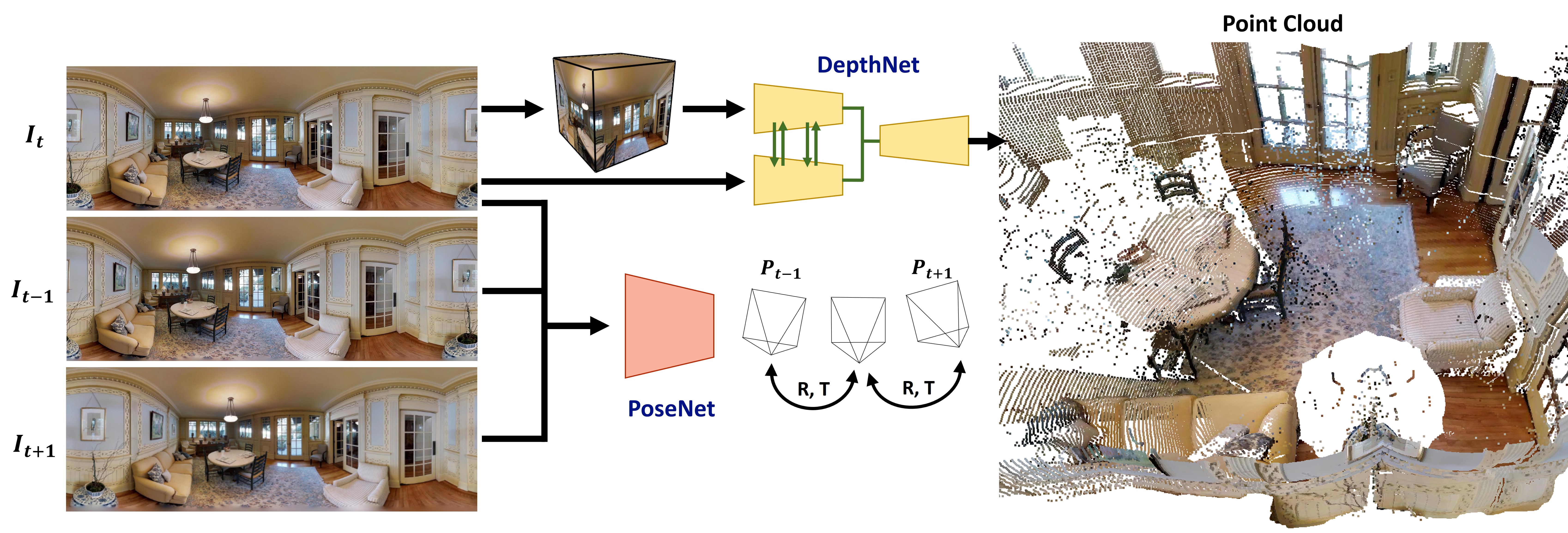
Due to the rise of spherical cameras, monocular 360 depth estimation becomes an important technique for many applications (e.g., autonomous systems). Thus, state-of-the-art frameworks for monocular 360 depth estimation such as bi-projection fusion in BiFuse are proposed. To train such a framework, a large number of panoramas along with the corresponding depth ground truths captured by laser sensors are required, which highly increases the cost of data collection. Moreover, since such a data collection procedure is time-consuming, the scalability of extending these methods to different scenes becomes a challenge. To this end, self-training a network for monocular depth estimation from 360 videos is one way to alleviate this issue. However, there are no existing frameworks that incorporate bi-projection fusion into the self-training scheme, which highly limits the self-supervised performance since bi-projection fusion can leverage information from different projection types. In this paper, we propose BiFuse++ to explore the combination of bi-projection fusion and the self-training scenario. To be specific, we propose a new fusion module and Contrast-Aware Photometric Loss to improve the performance of BiFuse and increase the stability of self-training on real-world videos. We conduct both supervised and self-supervised experiments on benchmark datasets and achieve state-of-the-art performance.
PDF Abstract


 SUNCG
SUNCG
 2D-3D-S
2D-3D-S

