BioWorkbench: A High-Performance Framework for Managing and Analyzing Bioinformatics Experiments
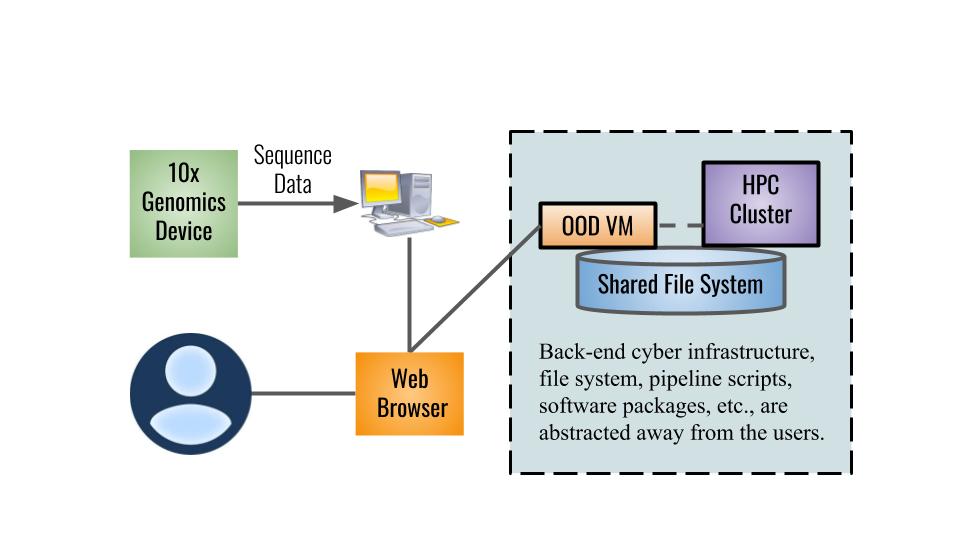
Advances in sequencing techniques have led to exponential growth in biological data, demanding the development of large-scale bioinformatics experiments. Because these experiments are computation- and data-intensive, they require high-performance computing (HPC) techniques and can benefit from specialized technologies such as Scientific Workflow Management Systems (SWfMS) and databases. In this work, we present BioWorkbench, a framework for managing and analyzing bioinformatics experiments. This framework automatically collects provenance data, including both performance data from workflow execution and data from the scientific domain of the workflow application. Provenance data can be analyzed through a web application that abstracts a set of queries to the provenance database, simplifying access to provenance information. We evaluate BioWorkbench using three case studies: SwiftPhylo, a phylogenetic tree assembly workflow; SwiftGECKO, a comparative genomics workflow; and RASflow, a RASopathy analysis workflow. We analyze each workflow from both computational and scientific domain perspectives, by using queries to a provenance and annotation database. Some of these queries are available as a pre-built feature of the BioWorkbench web application. Through the provenance data, we show that the framework is scalable and achieves high-performance, reducing up to 98% of the case studies execution time. We also show how the application of machine learning techniques can enrich the analysis process.
PDF Abstract