Black-Box Data-efficient Policy Search for Robotics
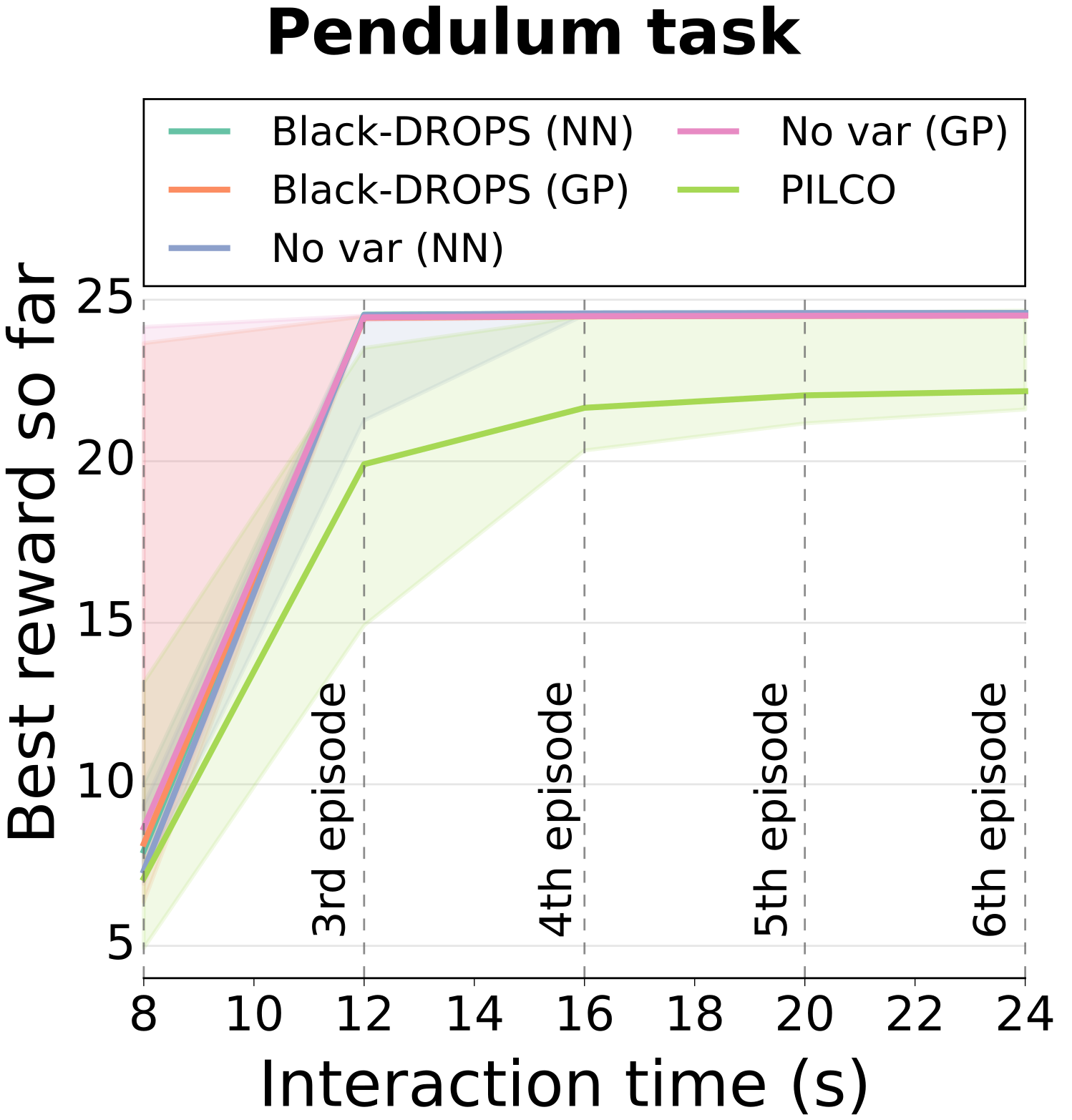
The most data-efficient algorithms for reinforcement learning (RL) in robotics are based on uncertain dynamical models: after each episode, they first learn a dynamical model of the robot, then they use an optimization algorithm to find a policy that maximizes the expected return given the model and its uncertainties. It is often believed that this optimization can be tractable only if analytical, gradient-based algorithms are used; however, these algorithms require using specific families of reward functions and policies, which greatly limits the flexibility of the overall approach. In this paper, we introduce a novel model-based RL algorithm, called Black-DROPS (Black-box Data-efficient RObot Policy Search) that: (1) does not impose any constraint on the reward function or the policy (they are treated as black-boxes), (2) is as data-efficient as the state-of-the-art algorithm for data-efficient RL in robotics, and (3) is as fast (or faster) than analytical approaches when several cores are available. The key idea is to replace the gradient-based optimization algorithm with a parallel, black-box algorithm that takes into account the model uncertainties. We demonstrate the performance of our new algorithm on two standard control benchmark problems (in simulation) and a low-cost robotic manipulator (with a real robot).
PDF Abstract
