BlonDe: An Automatic Evaluation Metric for Document-level Machine Translation
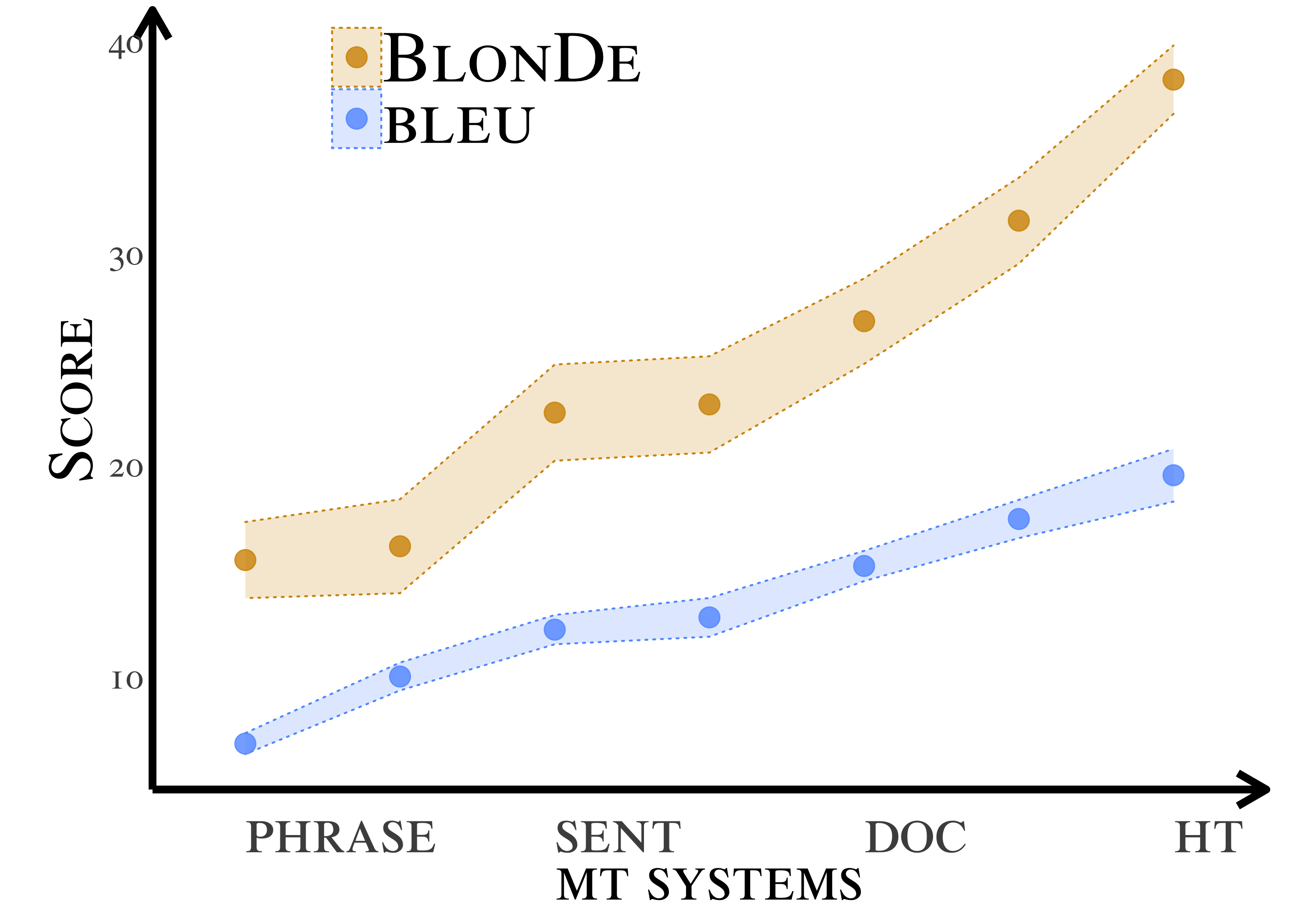
Standard automatic metrics, e.g. BLEU, are not reliable for document-level MT evaluation. They can neither distinguish document-level improvements in translation quality from sentence-level ones, nor identify the discourse phenomena that cause context-agnostic translations. This paper introduces a novel automatic metric BlonDe to widen the scope of automatic MT evaluation from sentence to document level. BlonDe takes discourse coherence into consideration by categorizing discourse-related spans and calculating the similarity-based F1 measure of categorized spans. We conduct extensive comparisons on a newly constructed dataset BWB. The experimental results show that BlonDe possesses better selectivity and interpretability at the document-level, and is more sensitive to document-level nuances. In a large-scale human study, BlonDe also achieves significantly higher Pearson's r correlation with human judgments compared to previous metrics.
PDF Abstract NAACL 2022 PDF NAACL 2022 Abstract

