Boosting Light-Weight Depth Estimation Via Knowledge Distillation
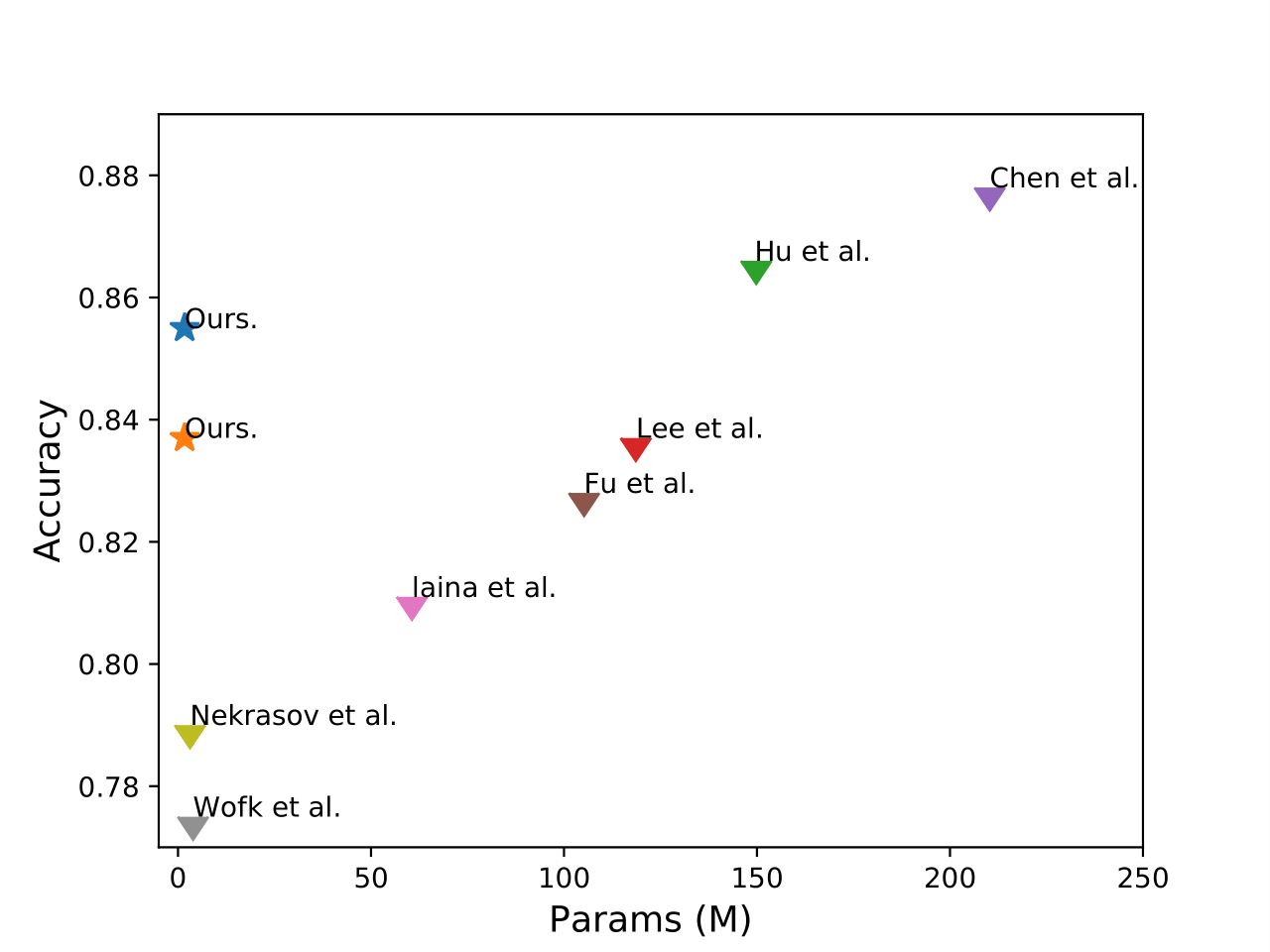
Monocular depth estimation (MDE) methods are often either too computationally expensive or not accurate enough due to the trade-off between model complexity and inference performance. In this paper, we propose a lightweight network that can accurately estimate depth maps using minimal computing resources. We achieve this by designing a compact model architecture that maximally reduces model complexity. To improve the performance of our lightweight network, we adopt knowledge distillation (KD) techniques. We consider a large network as an expert teacher that accurately estimates depth maps on the target domain. The student, which is the lightweight network, is then trained to mimic the teacher's predictions. However, this KD process can be challenging and insufficient due to the large model capacity gap between the teacher and the student. To address this, we propose to use auxiliary unlabeled data to guide KD, enabling the student to better learn from the teacher's predictions. This approach helps fill the gap between the teacher and the student, resulting in improved data-driven learning. Our extensive experiments show that our method achieves comparable performance to state-of-the-art methods while using only 1% of their parameters. Furthermore, our method outperforms previous lightweight methods regarding inference accuracy, computational efficiency, and generalizability.
PDF Abstract



 ImageNet
ImageNet
 ScanNet
ScanNet
 NYUv2
NYUv2
 SUN RGB-D
SUN RGB-D
