Bootstrapped Masked Autoencoders for Vision BERT Pretraining
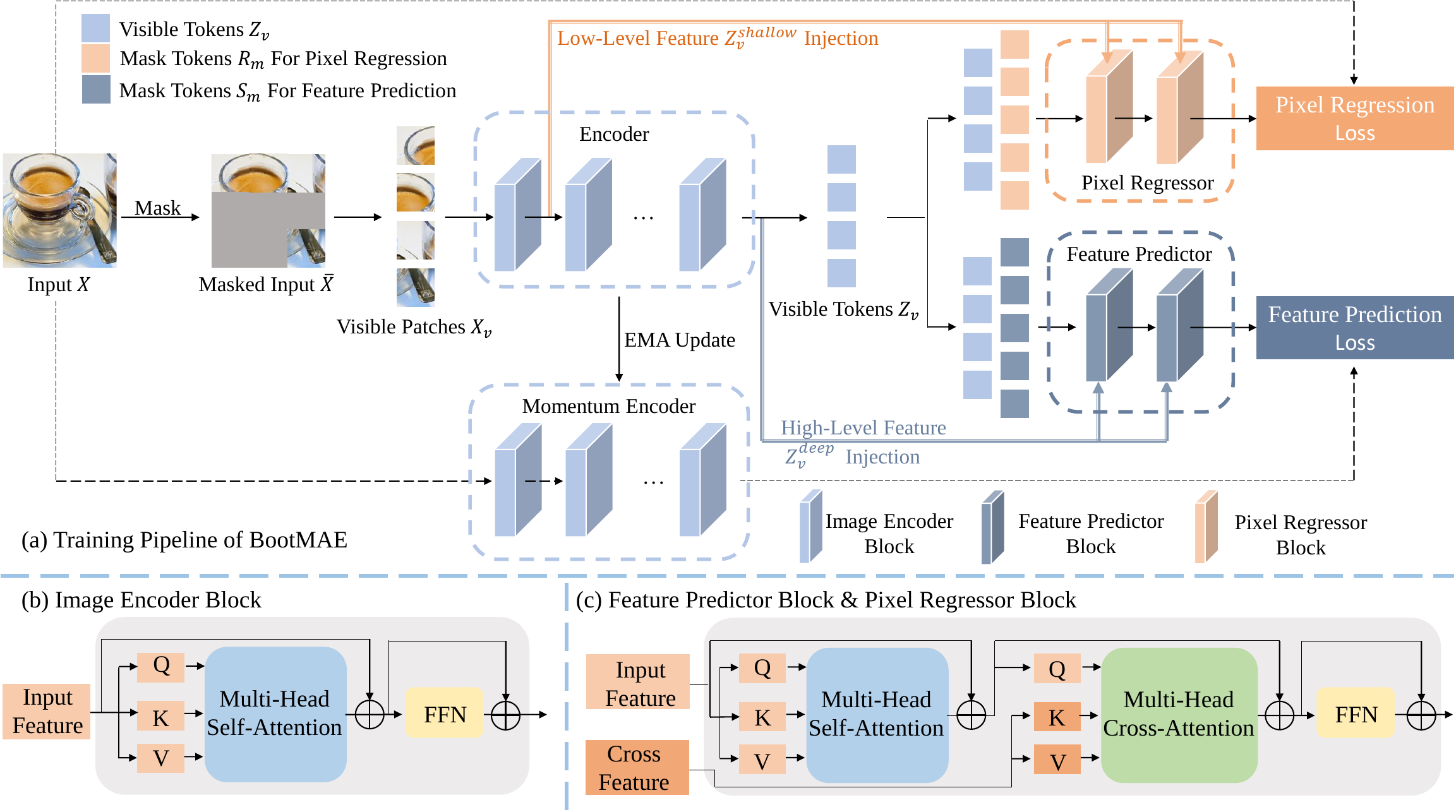
We propose bootstrapped masked autoencoders (BootMAE), a new approach for vision BERT pretraining. BootMAE improves the original masked autoencoders (MAE) with two core designs: 1) momentum encoder that provides online feature as extra BERT prediction targets; 2) target-aware decoder that tries to reduce the pressure on the encoder to memorize target-specific information in BERT pretraining. The first design is motivated by the observation that using a pretrained MAE to extract the features as the BERT prediction target for masked tokens can achieve better pretraining performance. Therefore, we add a momentum encoder in parallel with the original MAE encoder, which bootstraps the pretraining performance by using its own representation as the BERT prediction target. In the second design, we introduce target-specific information (e.g., pixel values of unmasked patches) from the encoder directly to the decoder to reduce the pressure on the encoder of memorizing the target-specific information. Thus, the encoder focuses on semantic modeling, which is the goal of BERT pretraining, and does not need to waste its capacity in memorizing the information of unmasked tokens related to the prediction target. Through extensive experiments, our BootMAE achieves $84.2\%$ Top-1 accuracy on ImageNet-1K with ViT-B backbone, outperforming MAE by $+0.8\%$ under the same pre-training epochs. BootMAE also gets $+1.0$ mIoU improvements on semantic segmentation on ADE20K and $+1.3$ box AP, $+1.4$ mask AP improvement on object detection and segmentation on COCO dataset. Code is released at https://github.com/LightDXY/BootMAE.
PDF Abstract



 ImageNet
ImageNet
 MS COCO
MS COCO
 ADE20K
ADE20K

