Breaking NLI Systems with Sentences that Require Simple Lexical Inferences
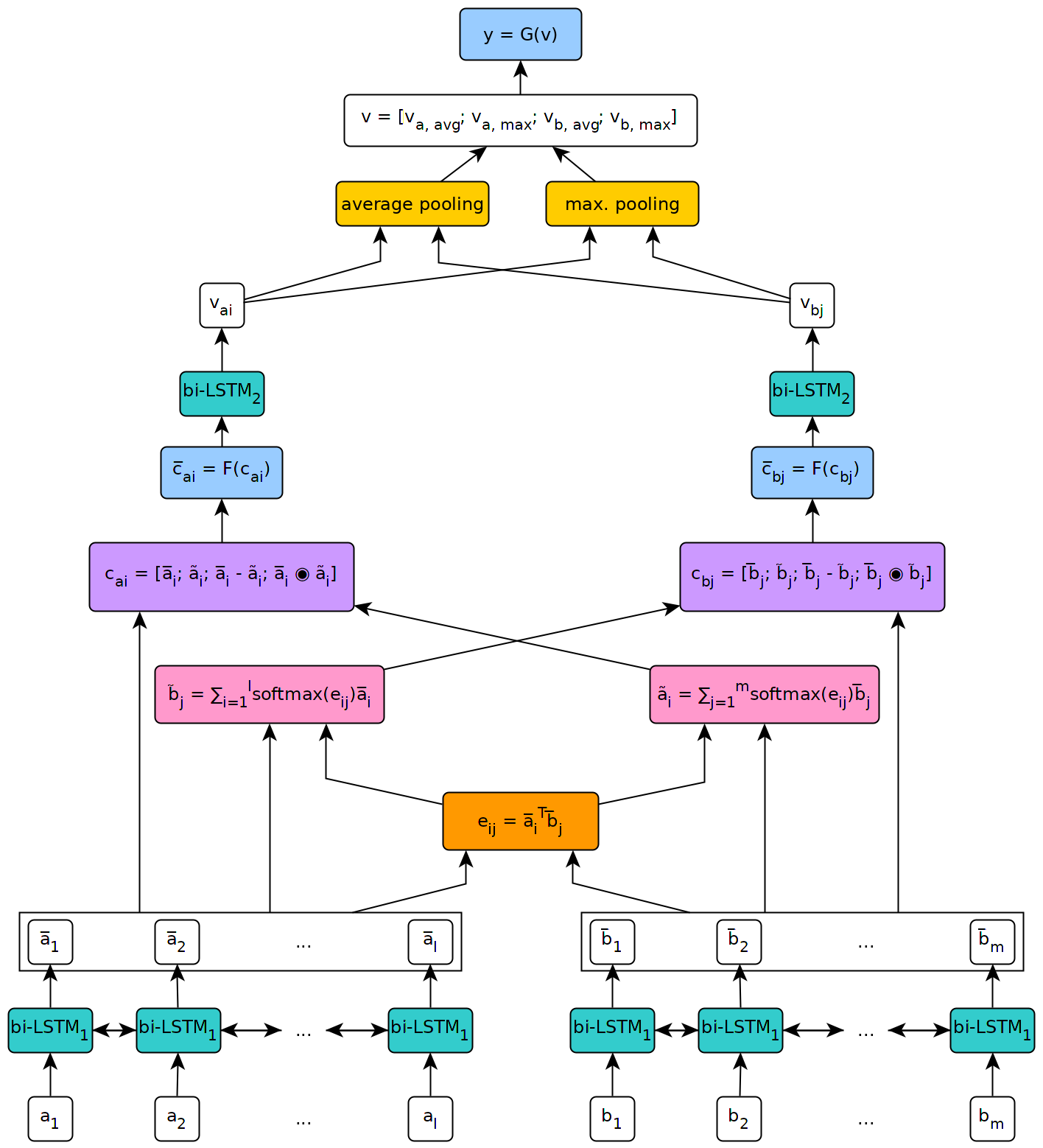
We create a new NLI test set that shows the deficiency of state-of-the-art models in inferences that require lexical and world knowledge. The new examples are simpler than the SNLI test set, containing sentences that differ by at most one word from sentences in the training set. Yet, the performance on the new test set is substantially worse across systems trained on SNLI, demonstrating that these systems are limited in their generalization ability, failing to capture many simple inferences.
PDF Abstract ACL 2018 PDF ACL 2018 AbstractCode

Tasks

 MultiNLI
MultiNLI
 SNLI
SNLI
Results from the Paper
Submit
results from this paper
to get state-of-the-art GitHub badges and help the
community compare results to other papers.
Methods
No methods listed for this paper. Add
relevant methods here
