BRIO: Bringing Order to Abstractive Summarization
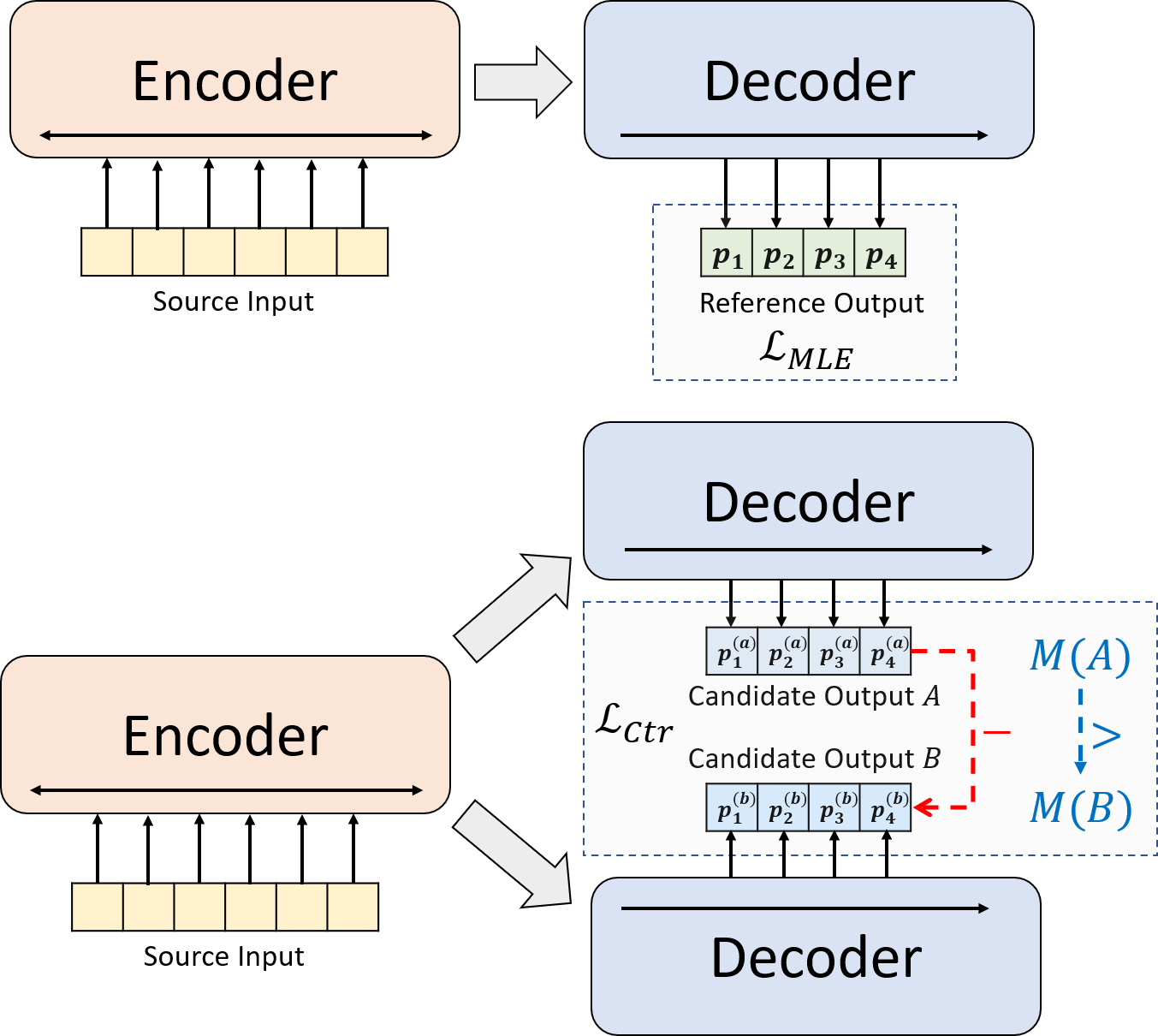
Abstractive summarization models are commonly trained using maximum likelihood estimation, which assumes a deterministic (one-point) target distribution in which an ideal model will assign all the probability mass to the reference summary. This assumption may lead to performance degradation during inference, where the model needs to compare several system-generated (candidate) summaries that have deviated from the reference summary. To address this problem, we propose a novel training paradigm which assumes a non-deterministic distribution so that different candidate summaries are assigned probability mass according to their quality. Our method achieves a new state-of-the-art result on the CNN/DailyMail (47.78 ROUGE-1) and XSum (49.07 ROUGE-1) datasets. Further analysis also shows that our model can estimate probabilities of candidate summaries that are more correlated with their level of quality.
PDF Abstract ACL 2022 PDF ACL 2022 AbstractCode




 CNN/Daily Mail
CNN/Daily Mail
 New York Times Annotated Corpus
New York Times Annotated Corpus
 XSum
XSum

| Task | Dataset | Model | Metric Name | Metric Value | Global Rank | Benchmark |
|---|---|---|---|---|---|---|
| Abstractive Text Summarization | CNN / Daily Mail | BRIO | ROUGE-1 | 47.78 | # 3 | |
| ROUGE-2 | 23.55 | # 2 | ||||
| ROUGE-L | 44.57 | # 3 | ||||
| Text Summarization | X-Sum | BRIO | ROUGE-1 | 49.07 | # 2 | |
| ROUGE-2 | 25.59 | # 2 | ||||
| ROUGE-3 | 40.40 | # 2 |
