
CAT-Seg: Cost Aggregation for Open-Vocabulary Semantic Segmentation
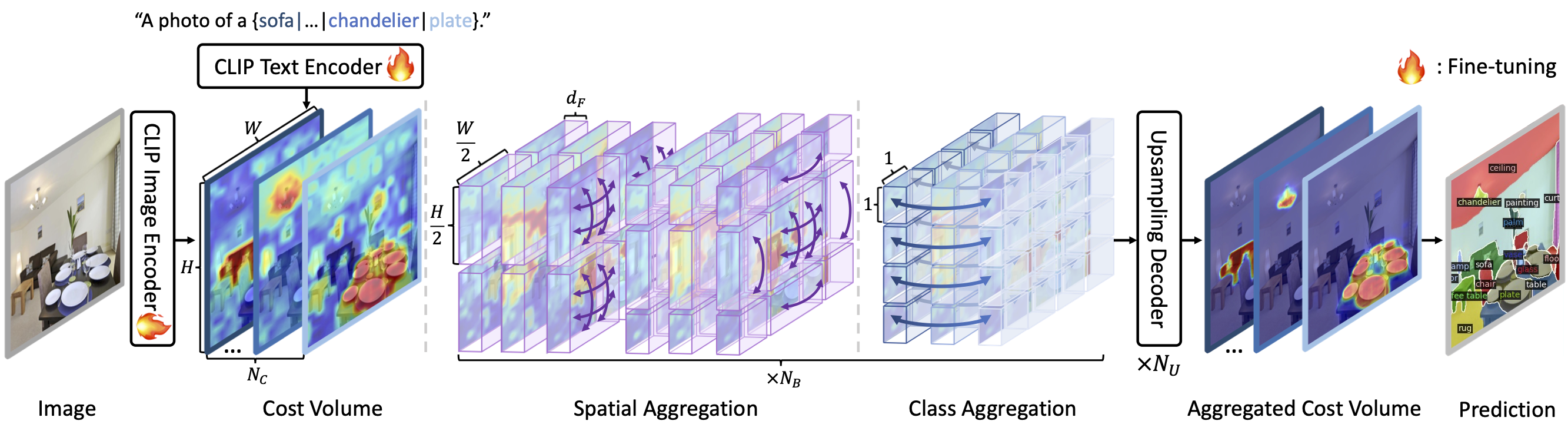
Open-vocabulary semantic segmentation presents the challenge of labeling each pixel within an image based on a wide range of text descriptions. In this work, we introduce a novel cost-based approach to adapt vision-language foundation models, notably CLIP, for the intricate task of semantic segmentation. Through aggregating the cosine similarity score, i.e., the cost volume between image and text embeddings, our method potently adapts CLIP for segmenting seen and unseen classes by fine-tuning its encoders, addressing the challenges faced by existing methods in handling unseen classes. Building upon this, we explore methods to effectively aggregate the cost volume considering its multi-modal nature of being established between image and text embeddings. Furthermore, we examine various methods for efficiently fine-tuning CLIP.
PDF Abstract Spaces
Spaces




 ADE20K
ADE20K
 PASCAL Context
PASCAL Context
 PASCAL VOC
PASCAL VOC

