CBNet: A Composite Backbone Network Architecture for Object Detection
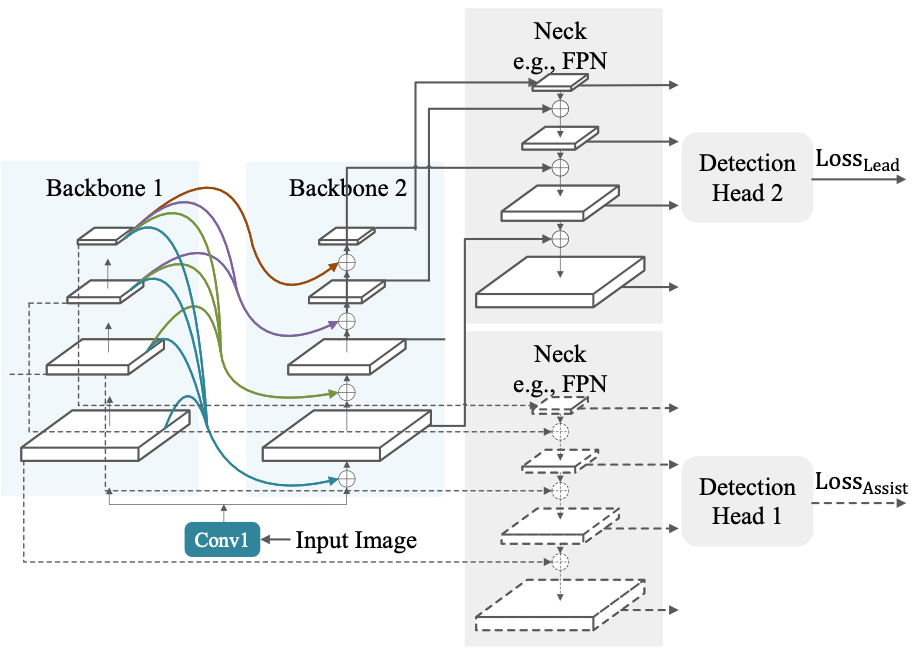
Modern top-performing object detectors depend heavily on backbone networks, whose advances bring consistent performance gains through exploring more effective network structures. In this paper, we propose a novel and flexible backbone framework, namely CBNetV2, to construct high-performance detectors using existing open-sourced pre-trained backbones under the pre-training fine-tuning paradigm. In particular, CBNetV2 architecture groups multiple identical backbones, which are connected through composite connections. Specifically, it integrates the high- and low-level features of multiple backbone networks and gradually expands the receptive field to more efficiently perform object detection. We also propose a better training strategy with assistant supervision for CBNet-based detectors. Without additional pre-training of the composite backbone, CBNetV2 can be adapted to various backbones (CNN-based vs. Transformer-based) and head designs of most mainstream detectors (one-stage vs. two-stage, anchor-based vs. anchor-free-based). Experiments provide strong evidence that, compared with simply increasing the depth and width of the network, CBNetV2 introduces a more efficient, effective, and resource-friendly way to build high-performance backbone networks. Particularly, our Dual-Swin-L achieves 59.4% box AP and 51.6% mask AP on COCO test-dev under the single-model and single-scale testing protocol, which is significantly better than the state-of-the-art result (57.7% box AP and 50.2% mask AP) achieved by Swin-L, while the training schedule is reduced by 6$\times$. With multi-scale testing, we push the current best single model result to a new record of 60.1% box AP and 52.3% mask AP without using extra training data. Code is available at https://github.com/VDIGPKU/CBNetV2.
PDF AbstractCode







 ImageNet
ImageNet
 MS COCO
MS COCO
 ssd
ssd
 COCO-O
COCO-O
Results from the Paper
 Ranked #6 on
Object Detection
on COCO-O
(using extra training data)
Ranked #6 on
Object Detection
on COCO-O
(using extra training data)
