CenterCLIP: Token Clustering for Efficient Text-Video Retrieval
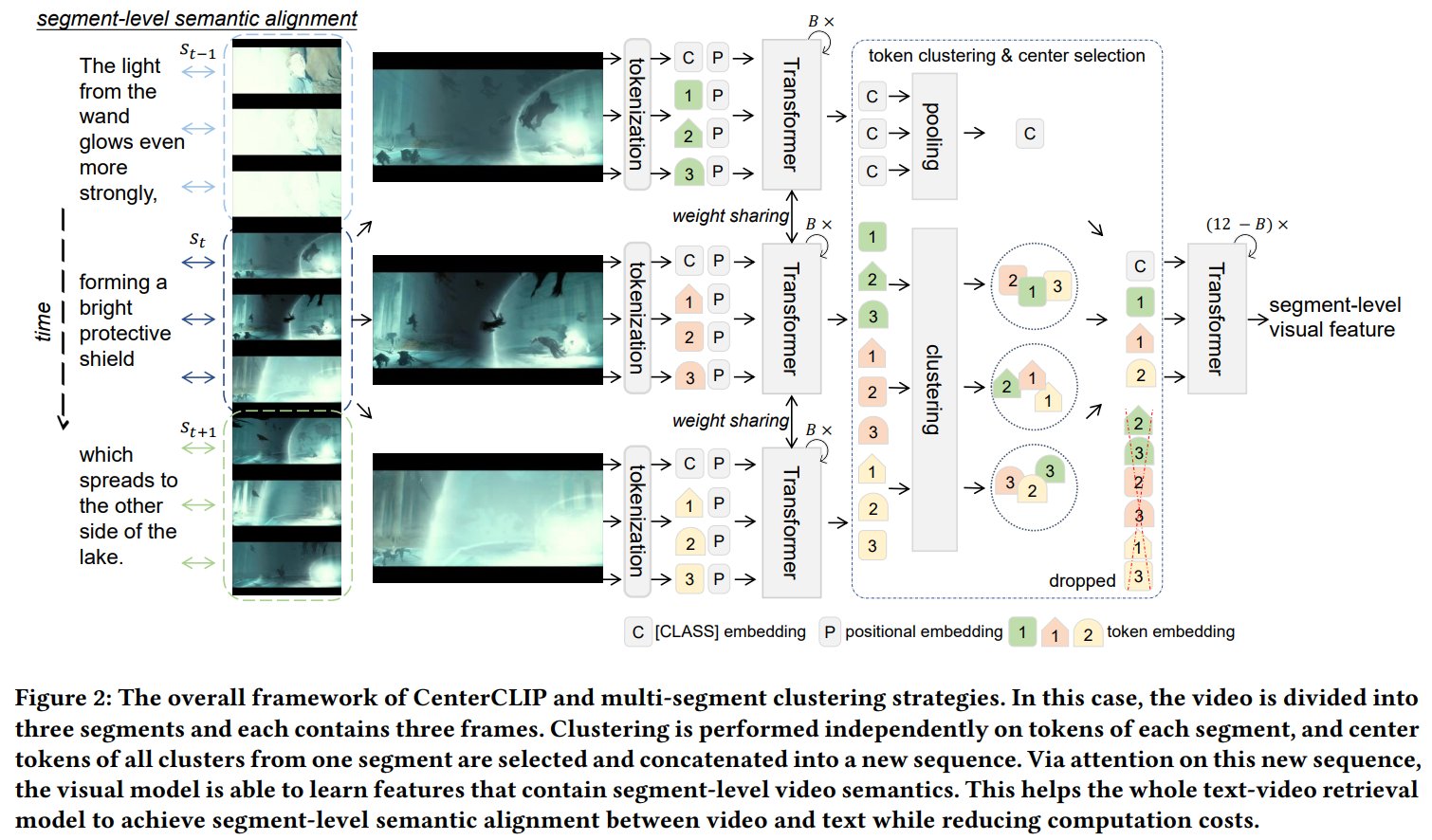
Recently, large-scale pre-training methods like CLIP have made great progress in multi-modal research such as text-video retrieval. In CLIP, transformers are vital for modeling complex multi-modal relations. However, in the vision transformer of CLIP, the essential visual tokenization process, which produces discrete visual token sequences, generates many homogeneous tokens due to the redundancy nature of consecutive and similar frames in videos. This significantly increases computation costs and hinders the deployment of video retrieval models in web applications. In this paper, to reduce the number of redundant video tokens, we design a multi-segment token clustering algorithm to find the most representative tokens and drop the non-essential ones. As the frame redundancy occurs mostly in consecutive frames, we divide videos into multiple segments and conduct segment-level clustering. Center tokens from each segment are later concatenated into a new sequence, while their original spatial-temporal relations are well maintained. We instantiate two clustering algorithms to efficiently find deterministic medoids and iteratively partition groups in high dimensional space. Through this token clustering and center selection procedure, we successfully reduce computation costs by removing redundant visual tokens. This method further enhances segment-level semantic alignment between video and text representations, enforcing the spatio-temporal interactions of tokens from within-segment frames. Our method, coined as CenterCLIP, surpasses existing state-of-the-art by a large margin on typical text-video benchmarks, while reducing the training memory cost by 35\% and accelerating the inference speed by 14\% at the best case. The code is available at \href{{https://github.com/mzhaoshuai/CenterCLIP}}{{https://github.com/mzhaoshuai/CenterCLIP}}.
PDF AbstractCode



Datasets
 ActivityNet
ActivityNet
 MSR-VTT
MSR-VTT
 MSVD
MSVD
 LSMDC
LSMDC
Results from the Paper
 Ranked #11 on
Video Retrieval
on MSVD
(using extra training data)
Ranked #11 on
Video Retrieval
on MSVD
(using extra training data)
