Channel-Wise Attention-Based Network for Self-Supervised Monocular Depth Estimation
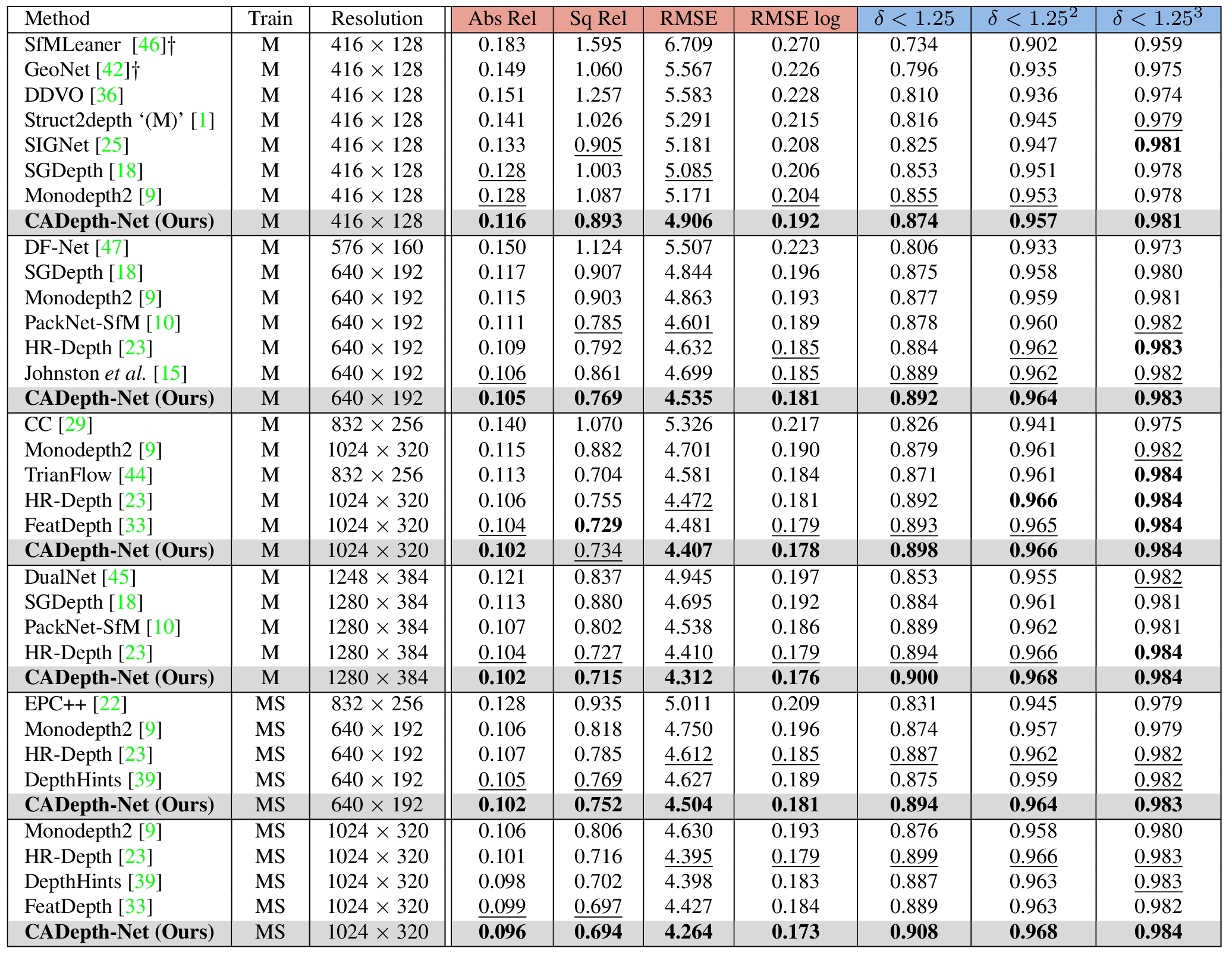
Self-supervised learning has shown very promising results for monocular depth estimation. Scene structure and local details both are significant clues for high-quality depth estimation. Recent works suffer from the lack of explicit modeling of scene structure and proper handling of details information, which leads to a performance bottleneck and blurry artefacts in predicted results. In this paper, we propose the Channel-wise Attention-based Depth Estimation Network (CADepth-Net) with two effective contributions: 1) The structure perception module employs the self-attention mechanism to capture long-range dependencies and aggregates discriminative features in channel dimensions, explicitly enhances the perception of scene structure, obtains the better scene understanding and rich feature representation. 2) The detail emphasis module re-calibrates channel-wise feature maps and selectively emphasizes the informative features, aiming to highlight crucial local details information and fuse different level features more efficiently, resulting in more precise and sharper depth prediction. Furthermore, the extensive experiments validate the effectiveness of our method and show that our model achieves the state-of-the-art results on the KITTI benchmark and Make3D datasets.
PDF Abstract




 KITTI
KITTI
 Make3D
Make3D

