Comprehensive Visual Question Answering on Point Clouds through Compositional Scene Manipulation
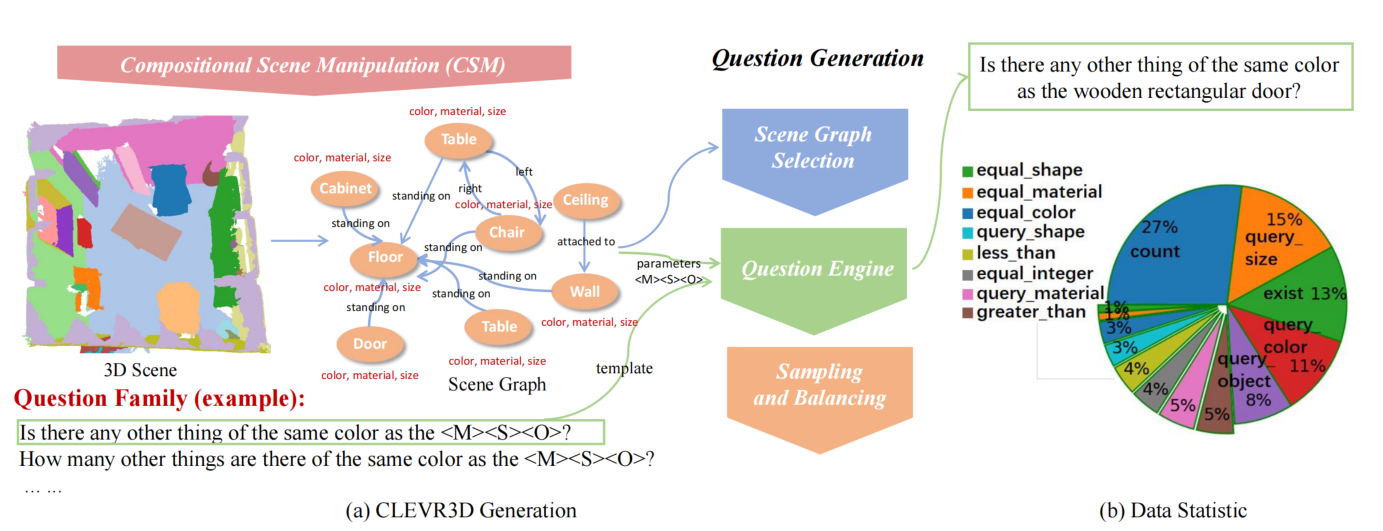
Visual Question Answering on 3D Point Cloud (VQA-3D) is an emerging yet challenging field that aims at answering various types of textual questions given an entire point cloud scene. To tackle this problem, we propose the CLEVR3D, a large-scale VQA-3D dataset consisting of 171K questions from 8,771 3D scenes. Specifically, we develop a question engine leveraging 3D scene graph structures to generate diverse reasoning questions, covering the questions of objects' attributes (i.e., size, color, and material) and their spatial relationships. Through such a manner, we initially generated 44K questions from 1,333 real-world scenes. Moreover, a more challenging setup is proposed to remove the confounding bias and adjust the context from a common-sense layout. Such a setup requires the network to achieve comprehensive visual understanding when the 3D scene is different from the general co-occurrence context (e.g., chairs always exist with tables). To this end, we further introduce the compositional scene manipulation strategy and generate 127K questions from 7,438 augmented 3D scenes, which can improve VQA-3D models for real-world comprehension. Built upon the proposed dataset, we baseline several VQA-3D models, where experimental results verify that the CLEVR3D can significantly boost other 3D scene understanding tasks. Our code and dataset will be made publicly available at https://github.com/yanx27/CLEVR3D.
PDF Abstract



 Visual Question Answering
Visual Question Answering
 CLEVR
CLEVR
 3DSSG
3DSSG
 3RScan
3RScan
