ClidSum: A Benchmark Dataset for Cross-Lingual Dialogue Summarization
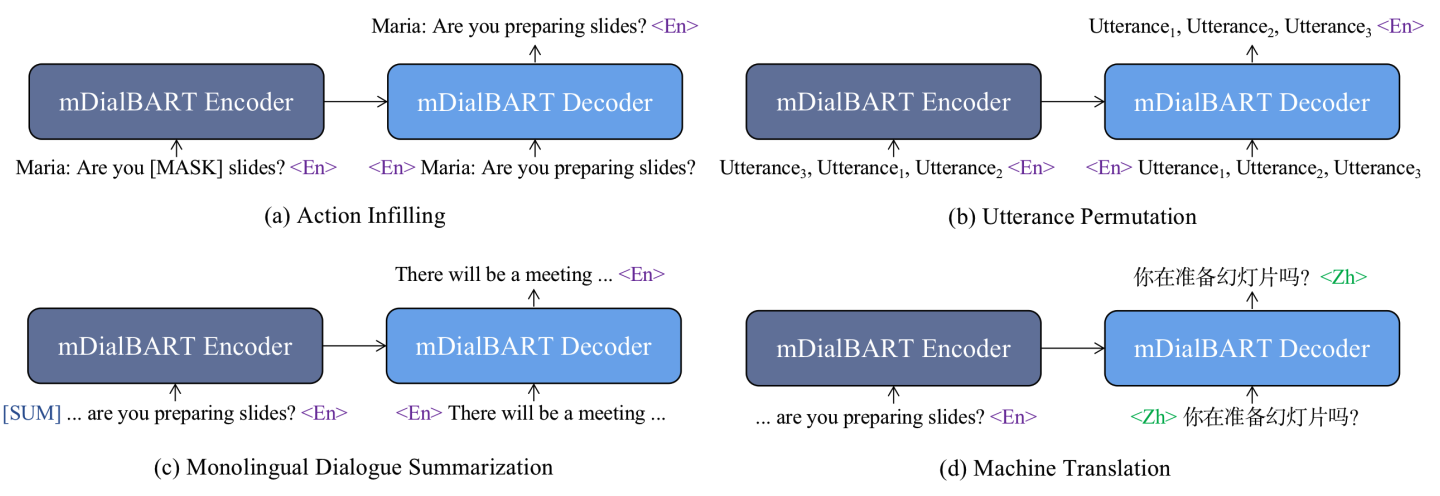
We present ClidSum, a benchmark dataset for building cross-lingual summarization systems on dialogue documents. It consists of 67k+ dialogue documents from two subsets (i.e., SAMSum and MediaSum) and 112k+ annotated summaries in different target languages. Based on the proposed ClidSum, we introduce two benchmark settings for supervised and semi-supervised scenarios, respectively. We then build various baseline systems in different paradigms (pipeline and end-to-end) and conduct extensive experiments on ClidSum to provide deeper analyses. Furthermore, we propose mDialBART which extends mBART-50 (a multi-lingual BART) via further pre-training. The multiple objectives used in the further pre-training stage help the pre-trained model capture the structural characteristics as well as important content in dialogues and the transformation from source to the target language. Experimental results show the superiority of mDialBART, as an end-to-end model, outperforms strong pipeline models on ClidSum. Finally, we discuss specific challenges that current approaches faced with this task and give multiple promising directions for future research. We have released the dataset and code at https://github.com/krystalan/ClidSum.
PDF Abstract
