CLIP-Count: Towards Text-Guided Zero-Shot Object Counting
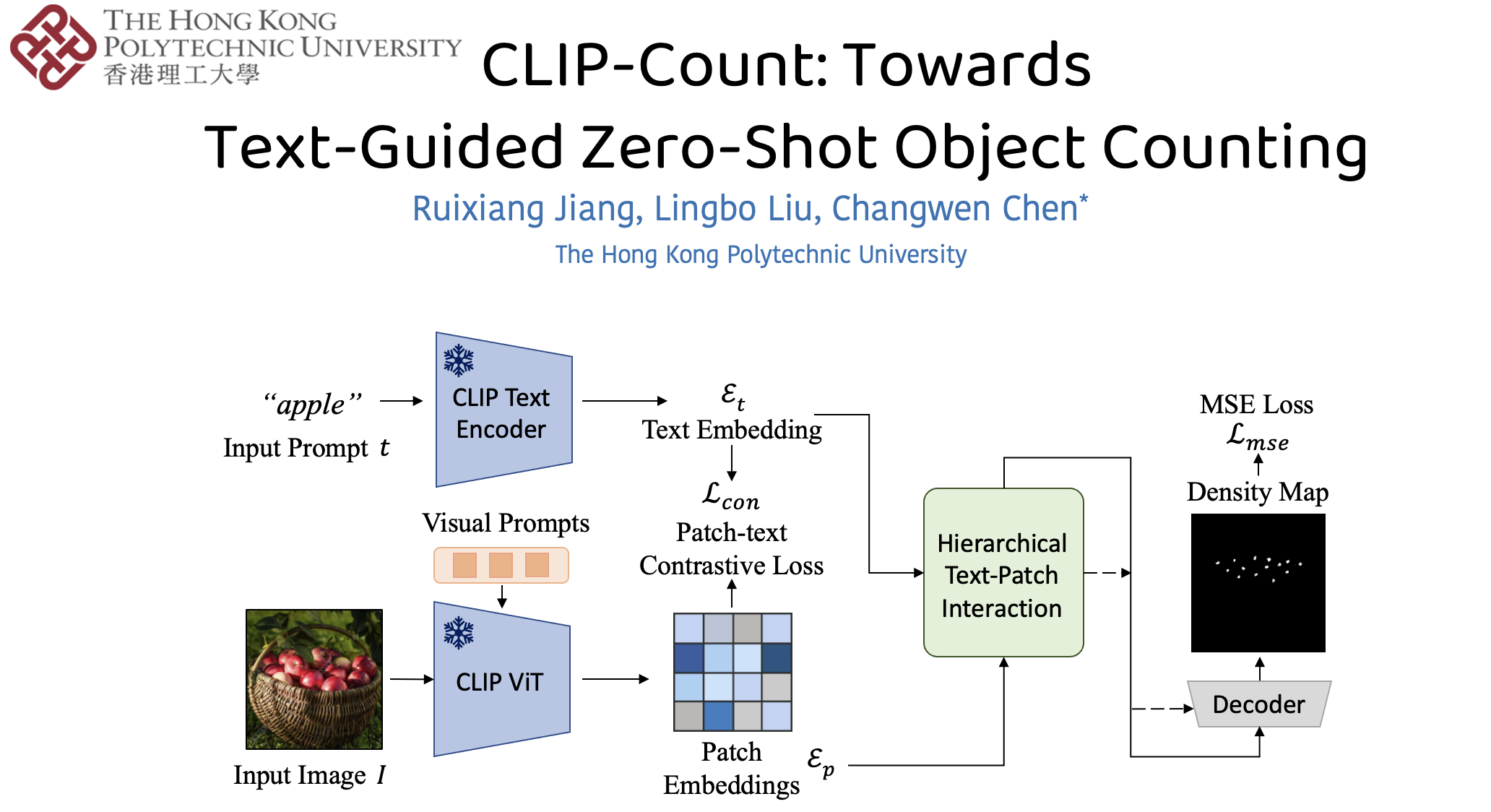
Recent advances in visual-language models have shown remarkable zero-shot text-image matching ability that is transferable to downstream tasks such as object detection and segmentation. Adapting these models for object counting, however, remains a formidable challenge. In this study, we first investigate transferring vision-language models (VLMs) for class-agnostic object counting. Specifically, we propose CLIP-Count, the first end-to-end pipeline that estimates density maps for open-vocabulary objects with text guidance in a zero-shot manner. To align the text embedding with dense visual features, we introduce a patch-text contrastive loss that guides the model to learn informative patch-level visual representations for dense prediction. Moreover, we design a hierarchical patch-text interaction module to propagate semantic information across different resolution levels of visual features. Benefiting from the full exploitation of the rich image-text alignment knowledge of pretrained VLMs, our method effectively generates high-quality density maps for objects-of-interest. Extensive experiments on FSC-147, CARPK, and ShanghaiTech crowd counting datasets demonstrate state-of-the-art accuracy and generalizability of the proposed method. Code is available: https://github.com/songrise/CLIP-Count.
PDF Abstract


 ShanghaiTech
ShanghaiTech
 CARPK
CARPK
 FSC147
FSC147

