CLIP4IDC: CLIP for Image Difference Captioning
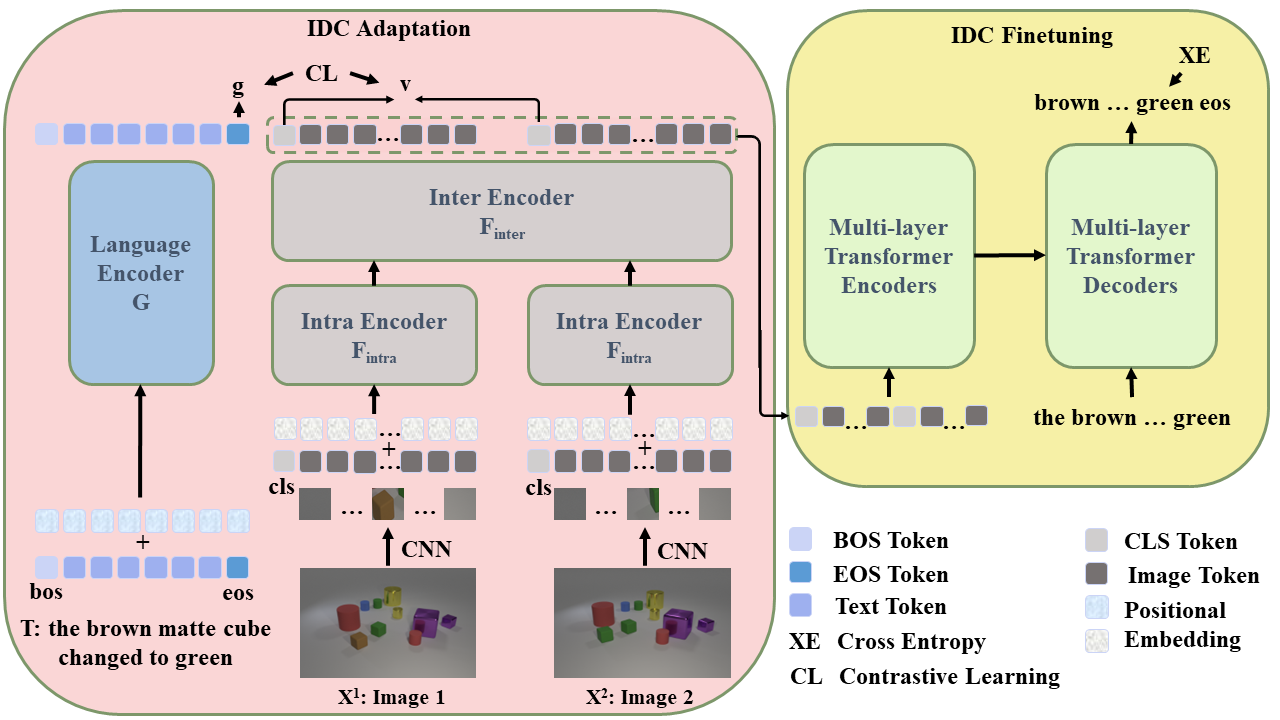
Image Difference Captioning (IDC) aims at generating sentences to describe differences between two similar-looking images. Conventional approaches learn an IDC model with a pre-trained and usually frozen visual feature extractor. Accordingly, two major issues may arise: (1) a large domain gap usually exists between the pre-training datasets used for training such a visual encoder and that of the downstream IDC task, and (2) the visual feature extractor, when separately encoding two images, often does not effectively encode the visual changes between two images. Due to the excellent zero-shot performance of the recently proposed CLIP, we thus propose CLIP4IDC to transfer a CLIP model for the IDC task to address those issues. Different from directly fine-tuning CLIP to generate sentences, we introduce an adaptation training process to adapt CLIP's visual encoder to capture and align differences in image pairs based on the textual descriptions. Experiments on three IDC benchmark datasets, CLEVR-Change, Spot-the-Diff, and Image-Editing-Request, demonstrate the effectiveness of CLIP4IDC.
PDF Abstract


 Spot-the-diff
Spot-the-diff
