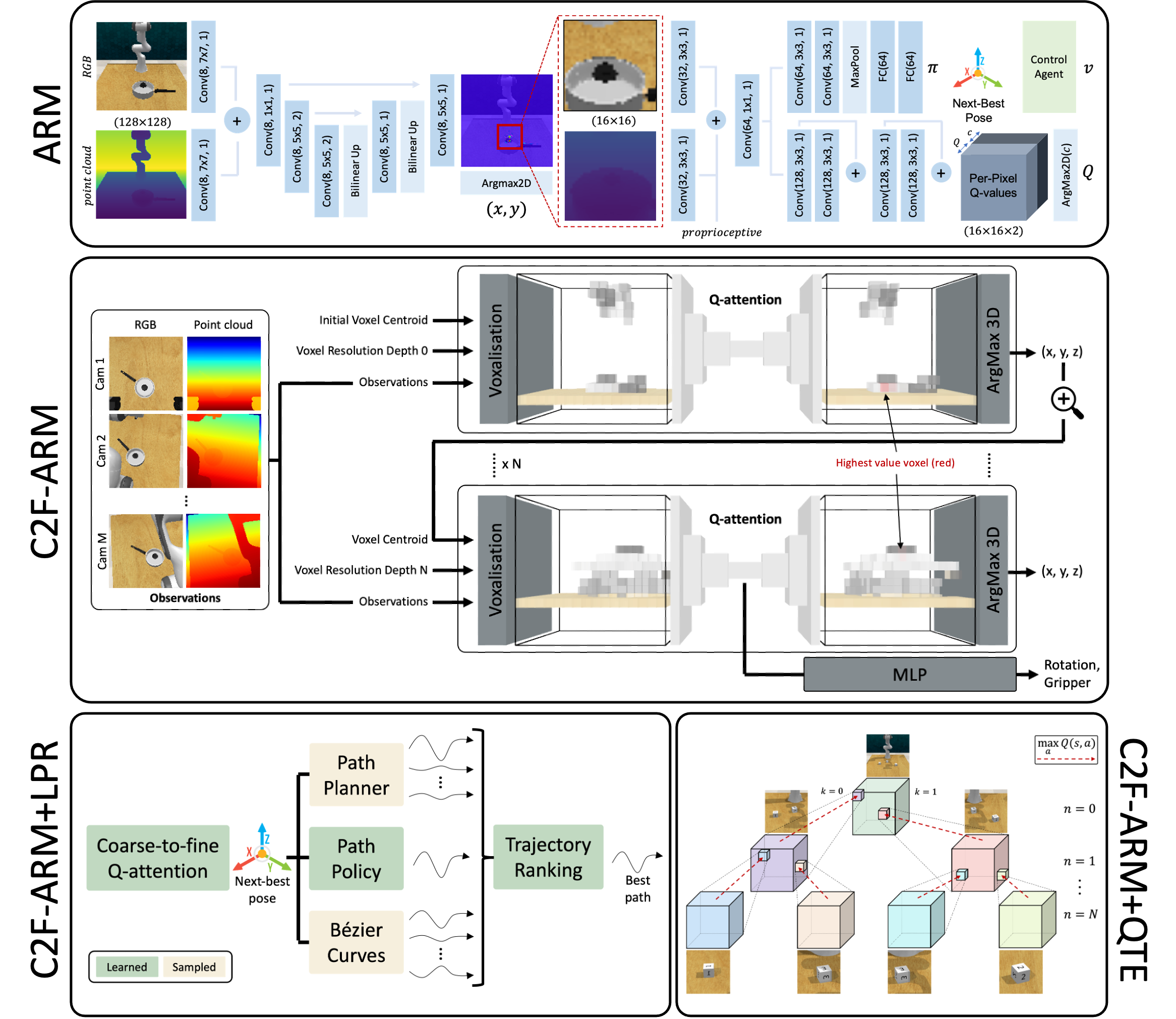
Coarse-to-fine Q-attention with Tree Expansion
Coarse-to-fine Q-attention enables sample-efficient robot manipulation by discretizing the translation space in a coarse-to-fine manner, where the resolution gradually increases at each layer in the hierarchy. Although effective, Q-attention suffers from "coarse ambiguity" - when voxelization is significantly coarse, it is not feasible to distinguish similar-looking objects without first inspecting at a finer resolution. To combat this, we propose to envision Q-attention as a tree that can be expanded and used to accumulate value estimates across the top-k voxels at each Q-attention depth. When our extension, Q-attention with Tree Expansion (QTE), replaces standard Q-attention in the Attention-driven Robot Manipulation (ARM) system, we are able to accomplish a larger set of tasks; especially on those that suffer from "coarse ambiguity". In addition to evaluating our approach across 12 RLBench tasks, we also show that the improved performance is visible in a real-world task involving small objects.
PDF Abstract

