COCO-LM: Correcting and Contrasting Text Sequences for Language Model Pretraining
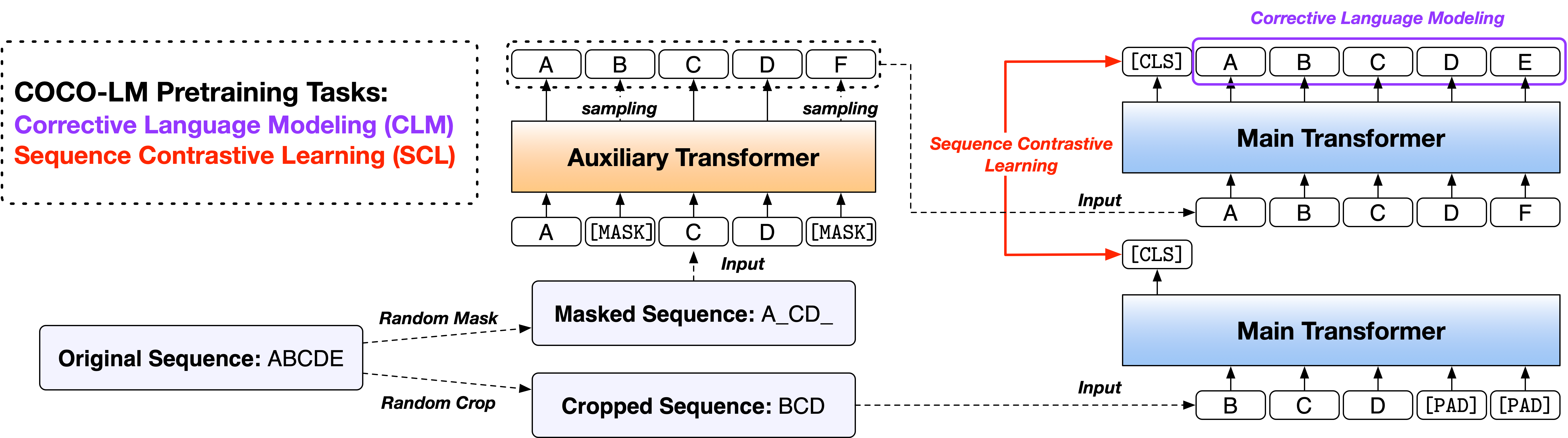
We present a self-supervised learning framework, COCO-LM, that pretrains Language Models by COrrecting and COntrasting corrupted text sequences. Following ELECTRA-style pretraining, COCO-LM employs an auxiliary language model to corrupt text sequences, upon which it constructs two new tasks for pretraining the main model. The first token-level task, Corrective Language Modeling, is to detect and correct tokens replaced by the auxiliary model, in order to better capture token-level semantics. The second sequence-level task, Sequence Contrastive Learning, is to align text sequences originated from the same source input while ensuring uniformity in the representation space. Experiments on GLUE and SQuAD demonstrate that COCO-LM not only outperforms recent state-of-the-art pretrained models in accuracy, but also improves pretraining efficiency. It achieves the MNLI accuracy of ELECTRA with 50% of its pretraining GPU hours. With the same pretraining steps of standard base/large-sized models, COCO-LM outperforms the previous best models by 1+ GLUE average points.
PDF Abstract NeurIPS 2021 PDF NeurIPS 2021 Abstract



 GLUE
GLUE
 SST
SST
 SQuAD
SQuAD
 MultiNLI
MultiNLI
 QNLI
QNLI
 MRPC
MRPC
 C4
C4
 CoLA
CoLA
 BookCorpus
BookCorpus
