Data Structures & Algorithms for Exact Inference in Hierarchical Clustering
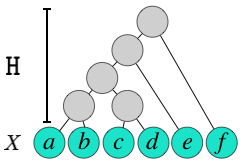
Hierarchical clustering is a fundamental task often used to discover meaningful structures in data, such as phylogenetic trees, taxonomies of concepts, subtypes of cancer, and cascades of particle decays in particle physics. Typically approximate algorithms are used for inference due to the combinatorial number of possible hierarchical clusterings. In contrast to existing methods, we present novel dynamic-programming algorithms for \emph{exact} inference in hierarchical clustering based on a novel trellis data structure, and we prove that we can exactly compute the partition function, maximum likelihood hierarchy, and marginal probabilities of sub-hierarchies and clusters. Our algorithms scale in time and space proportional to the powerset of $N$ elements which is super-exponentially more efficient than explicitly considering each of the (2N-3)!! possible hierarchies. Also, for larger datasets where our exact algorithms become infeasible, we introduce an approximate algorithm based on a sparse trellis that compares well to other benchmarks. Exact methods are relevant to data analyses in particle physics and for finding correlations among gene expression in cancer genomics, and we give examples in both areas, where our algorithms outperform greedy and beam search baselines. In addition, we consider Dasgupta's cost with synthetic data.
PDF Abstract

