Comparative Analysis of CNN-based Spatiotemporal Reasoning in Videos
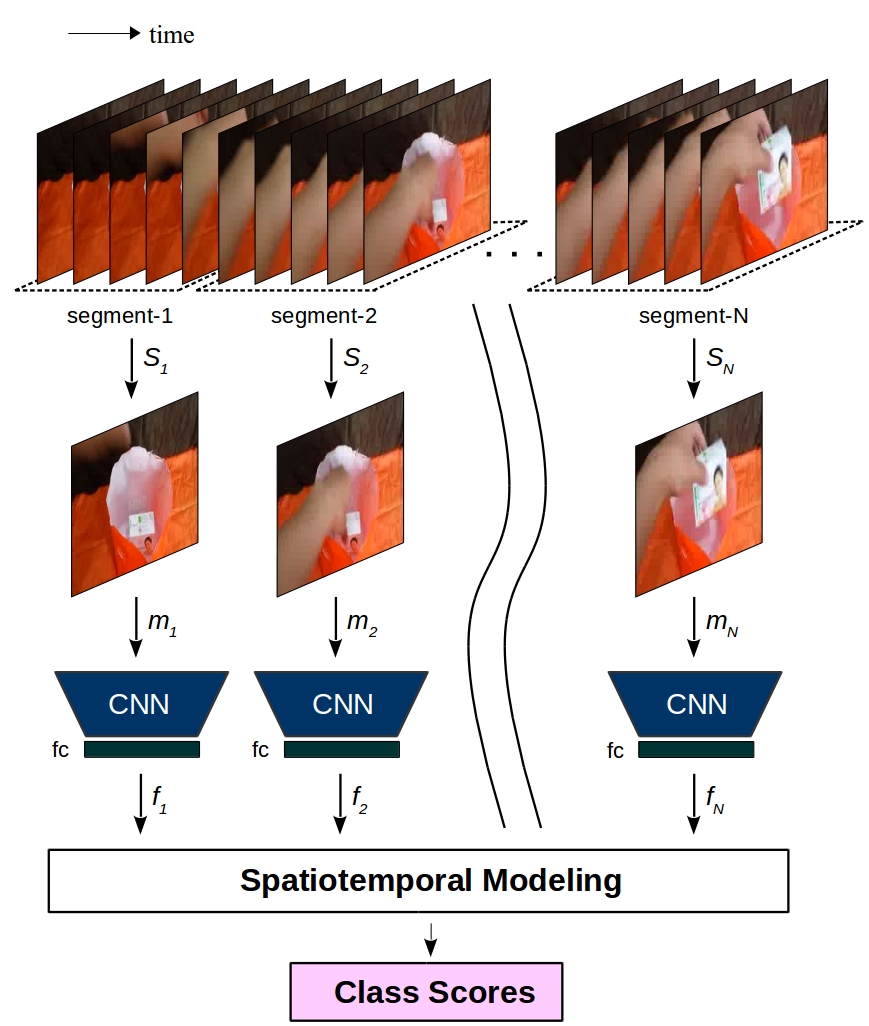
Understanding actions and gestures in video streams requires temporal reasoning of the spatial content from different time instants, i.e., spatiotemporal (ST) modeling. In this survey paper, we have made a comparative analysis of different ST modeling techniques for action and gecture recognition tasks. Since Convolutional Neural Networks (CNNs) are proved to be an effective tool as a feature extractor for static images, we apply ST modeling techniques on the features of static images from different time instants extracted by CNNs. All techniques are trained end-to-end together with a CNN feature extraction part and evaluated on two publicly available benchmarks: The Jester and the Something-Something datasets. The Jester dataset contains various dynamic and static hand gestures, whereas the Something-Something dataset contains actions of human-object interactions. The common characteristic of these two benchmarks is that the designed architectures need to capture the full temporal content of videos in order to correctly classify actions/gestures. Contrary to expectations, experimental results show that Recurrent Neural Network (RNN) based ST modeling techniques yield inferior results compared to other techniques such as fully convolutional architectures. Codes and pretrained models of this work are publicly available.
PDF Abstract


Datasets
 Something-Something V2
Something-Something V2
Results from the Paper
 Ranked #117 on
Action Recognition
on Something-Something V2
Ranked #117 on
Action Recognition
on Something-Something V2
