CompFeat: Comprehensive Feature Aggregation for Video Instance Segmentation
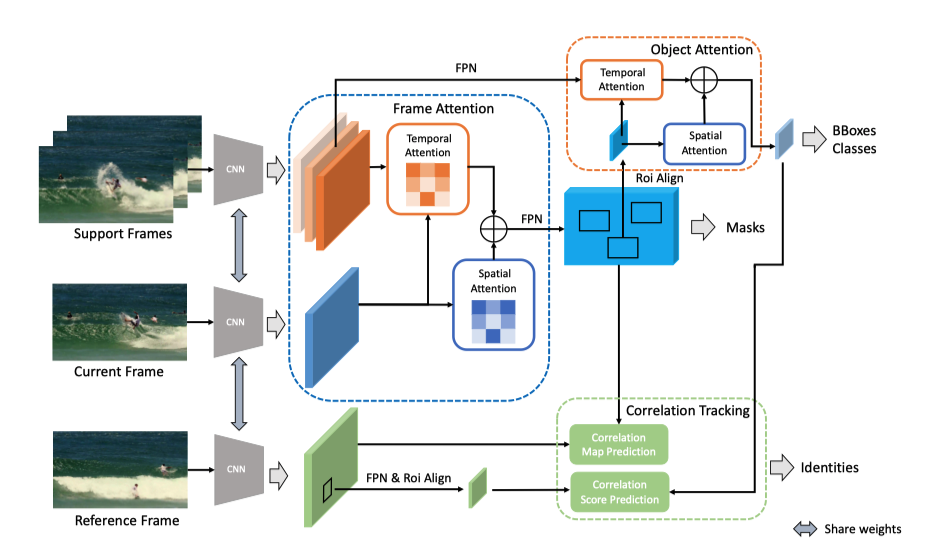
Video instance segmentation is a complex task in which we need to detect, segment, and track each object for any given video. Previous approaches only utilize single-frame features for the detection, segmentation, and tracking of objects and they suffer in the video scenario due to several distinct challenges such as motion blur and drastic appearance change. To eliminate ambiguities introduced by only using single-frame features, we propose a novel comprehensive feature aggregation approach (CompFeat) to refine features at both frame-level and object-level with temporal and spatial context information. The aggregation process is carefully designed with a new attention mechanism which significantly increases the discriminative power of the learned features. We further improve the tracking capability of our model through a siamese design by incorporating both feature similarities and spatial similarities. Experiments conducted on the YouTube-VIS dataset validate the effectiveness of proposed CompFeat. Our code will be available at https://github.com/SHI-Labs/CompFeat-for-Video-Instance-Segmentation.
PDF Abstract



 MS COCO
MS COCO
 YouTube-VIS 2019
YouTube-VIS 2019

