COMPOSER: Compositional Reasoning of Group Activity in Videos with Keypoint-Only Modality
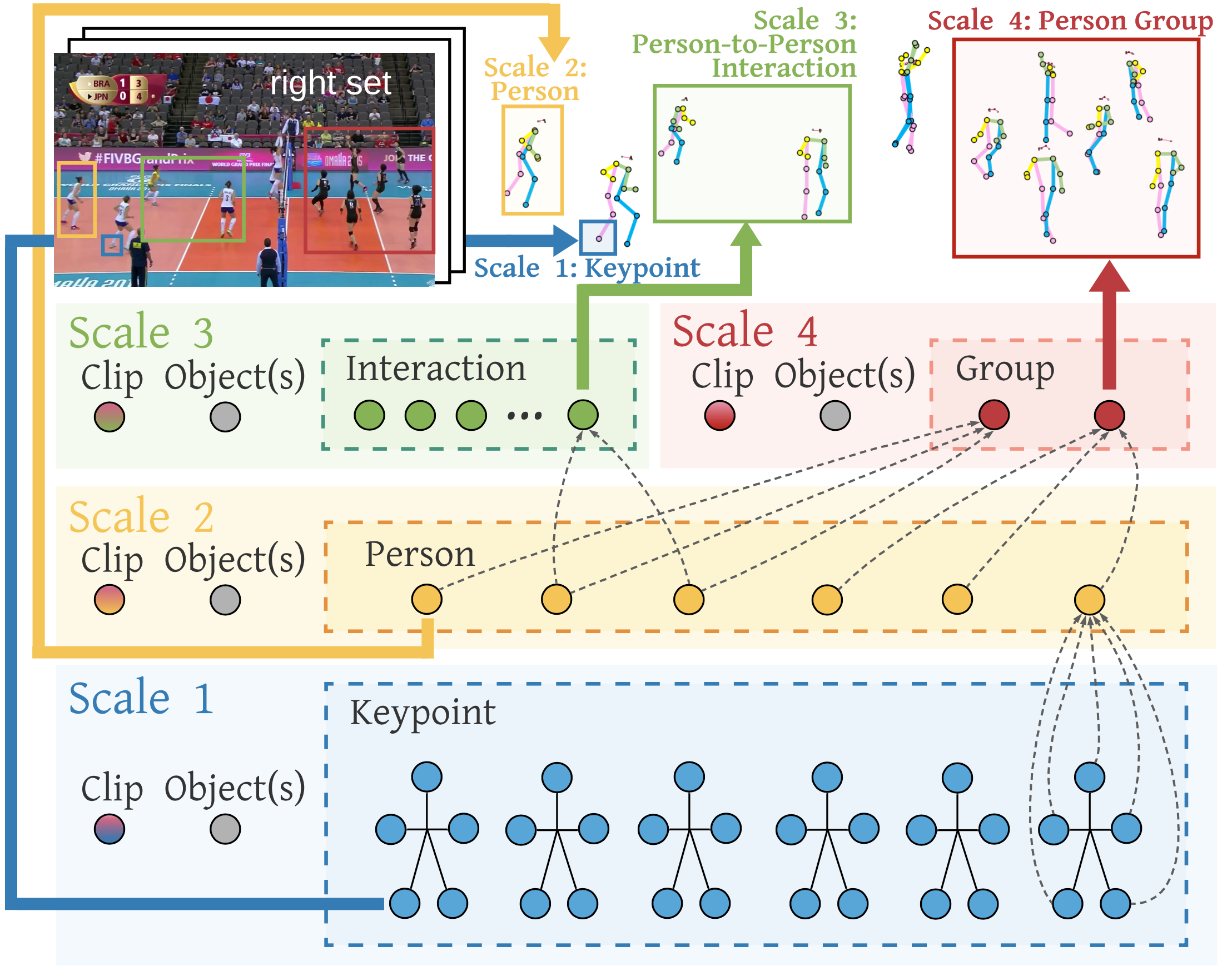
Group Activity Recognition detects the activity collectively performed by a group of actors, which requires compositional reasoning of actors and objects. We approach the task by modeling the video as tokens that represent the multi-scale semantic concepts in the video. We propose COMPOSER, a Multiscale Transformer based architecture that performs attention-based reasoning over tokens at each scale and learns group activity compositionally. In addition, prior works suffer from scene biases with privacy and ethical concerns. We only use the keypoint modality which reduces scene biases and prevents acquiring detailed visual data that may contain private or biased information of users. We improve the multiscale representations in COMPOSER by clustering the intermediate scale representations, while maintaining consistent cluster assignments between scales. Finally, we use techniques such as auxiliary prediction and data augmentations tailored to the keypoint signals to aid model training. We demonstrate the model's strength and interpretability on two widely-used datasets (Volleyball and Collective Activity). COMPOSER achieves up to +5.4% improvement with just the keypoint modality. Code is available at https://github.com/hongluzhou/composer
PDF Abstract

 Volleyball
Volleyball
 Collective Activity
Collective Activity

