Compressed Video Action Recognition
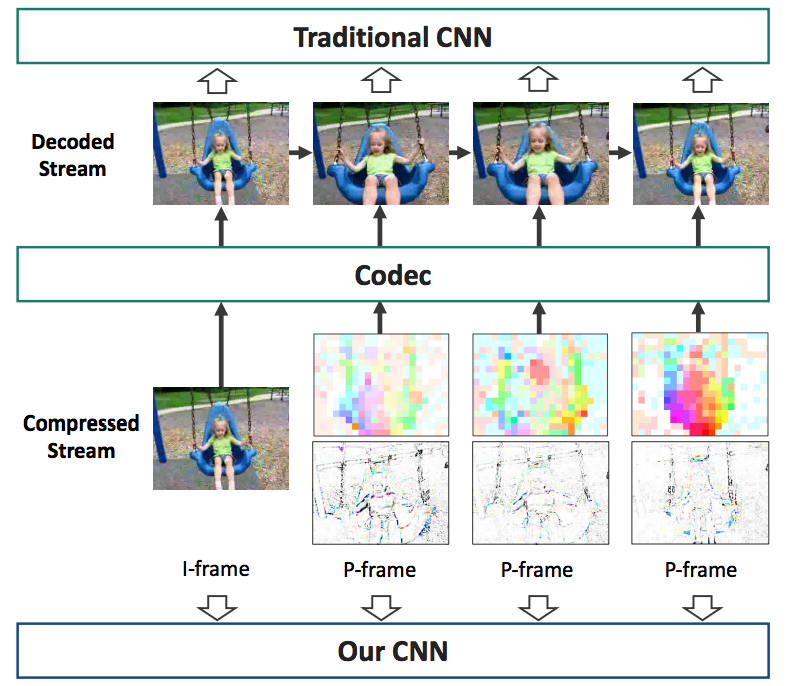
Training robust deep video representations has proven to be much more challenging than learning deep image representations. This is in part due to the enormous size of raw video streams and the high temporal redundancy; the true and interesting signal is often drowned in too much irrelevant data. Motivated by that the superfluous information can be reduced by up to two orders of magnitude by video compression (using H.264, HEVC, etc.), we propose to train a deep network directly on the compressed video. This representation has a higher information density, and we found the training to be easier. In addition, the signals in a compressed video provide free, albeit noisy, motion information. We propose novel techniques to use them effectively. Our approach is about 4.6 times faster than Res3D and 2.7 times faster than ResNet-152. On the task of action recognition, our approach outperforms all the other methods on the UCF-101, HMDB-51, and Charades dataset.
PDF Abstract CVPR 2018 PDF CVPR 2018 AbstractCode





 UCF101
UCF101
 HMDB51
HMDB51
 Charades
Charades
Results from the Paper
 Ranked #46 on
Action Classification
on Charades
(using extra training data)
Ranked #46 on
Action Classification
on Charades
(using extra training data)
