Compressing Multisets with Large Alphabets using Bits-Back Coding
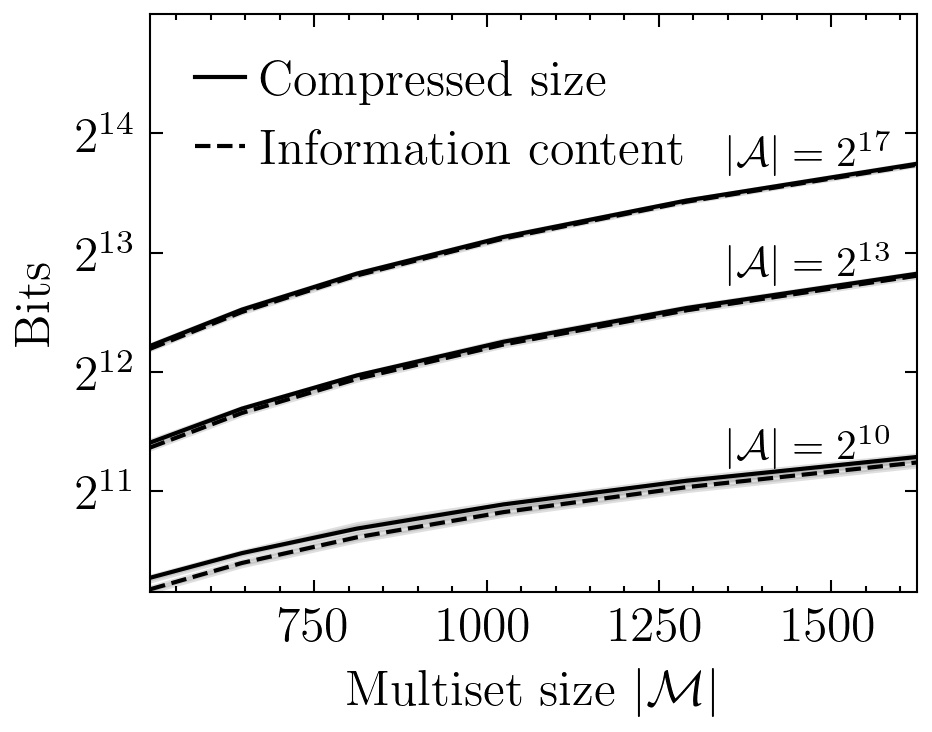
Current methods which compress multisets at an optimal rate have computational complexity that scales linearly with alphabet size, making them too slow to be practical in many real-world settings. We show how to convert a compression algorithm for sequences into one for multisets, in exchange for an additional complexity term that is quasi-linear in sequence length. This allows us to compress multisets of exchangeable symbols at an optimal rate, with computational complexity decoupled from the alphabet size. The key insight is to avoid encoding the multiset directly, and instead compress a proxy sequence, using a technique called `bits-back coding'. We demonstrate the method experimentally on tasks which are intractable with previous optimal-rate methods: compression of multisets of images and JavaScript Object Notation (JSON) files. Code for our experiments is available at https://github.com/facebookresearch/multiset-compression.
PDF Abstract MNIST
MNIST
