Compressing Sentence Representation for Semantic Retrieval via Homomorphic Projective Distillation
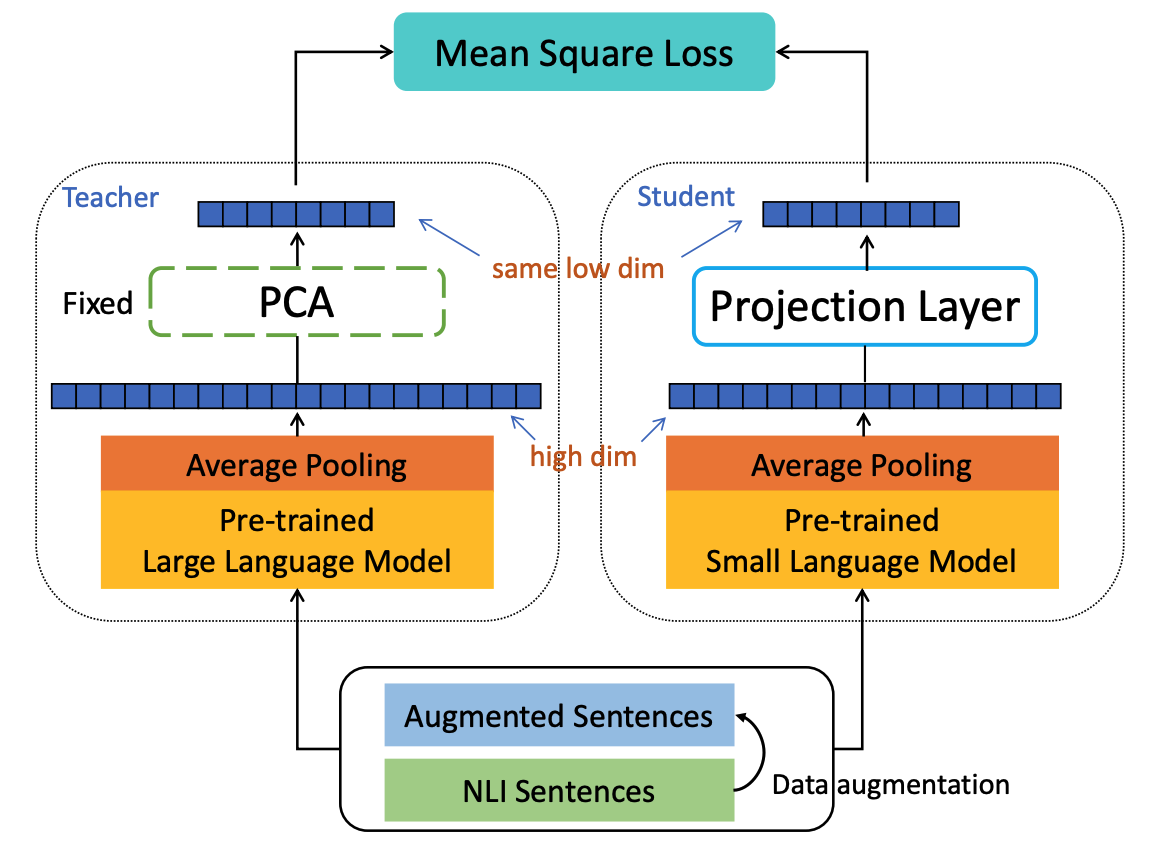
How to learn highly compact yet effective sentence representation? Pre-trained language models have been effective in many NLP tasks. However, these models are often huge and produce large sentence embeddings. Moreover, there is a big performance gap between large and small models. In this paper, we propose Homomorphic Projective Distillation (HPD) to learn compressed sentence embeddings. Our method augments a small Transformer encoder model with learnable projection layers to produce compact representations while mimicking a large pre-trained language model to retain the sentence representation quality. We evaluate our method with different model sizes on both semantic textual similarity (STS) and semantic retrieval (SR) tasks. Experiments show that our method achieves 2.7-4.5 points performance gain on STS tasks compared with previous best representations of the same size. In SR tasks, our method improves retrieval speed (8.2$\times$) and memory usage (8.0$\times$) compared with state-of-the-art large models.
PDF Abstract Findings (ACL) 2022 PDF Findings (ACL) 2022 Abstract



 MultiNLI
MultiNLI
 SNLI
SNLI
 SICK
SICK
