Confident Sinkhorn Allocation for Pseudo-Labeling
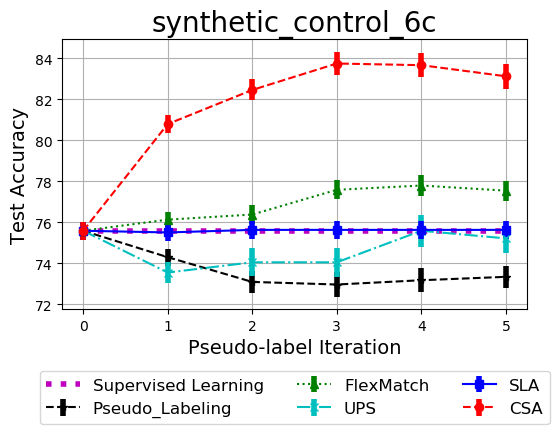
Semi-supervised learning is a critical tool in reducing machine learning's dependence on labeled data. It has been successfully applied to structured data, such as images and natural language, by exploiting the inherent spatial and semantic structure therein with pretrained models or data augmentation. These methods are not applicable, however, when the data does not have the appropriate structure, or invariances. Due to their simplicity, pseudo-labeling (PL) methods can be widely used without any domain assumptions. However, the greedy mechanism in PL is sensitive to a threshold and can perform poorly if wrong assignments are made due to overconfidence. This paper studies theoretically the role of uncertainty to pseudo-labeling and proposes Confident Sinkhorn Allocation (CSA), which identifies the best pseudo-label allocation via optimal transport to only samples with high confidence scores. CSA outperforms the current state-of-the-art in this practically important area of semi-supervised learning. Additionally, we propose to use the Integral Probability Metrics to extend and improve the existing PACBayes bound which relies on the Kullback-Leibler (KL) divergence, for ensemble models. Our code is publicly available at https://github.com/amzn/confident-sinkhorn-allocation.
PDF Abstract Colab
Colab


