Continual Local Training for Better Initialization of Federated Models
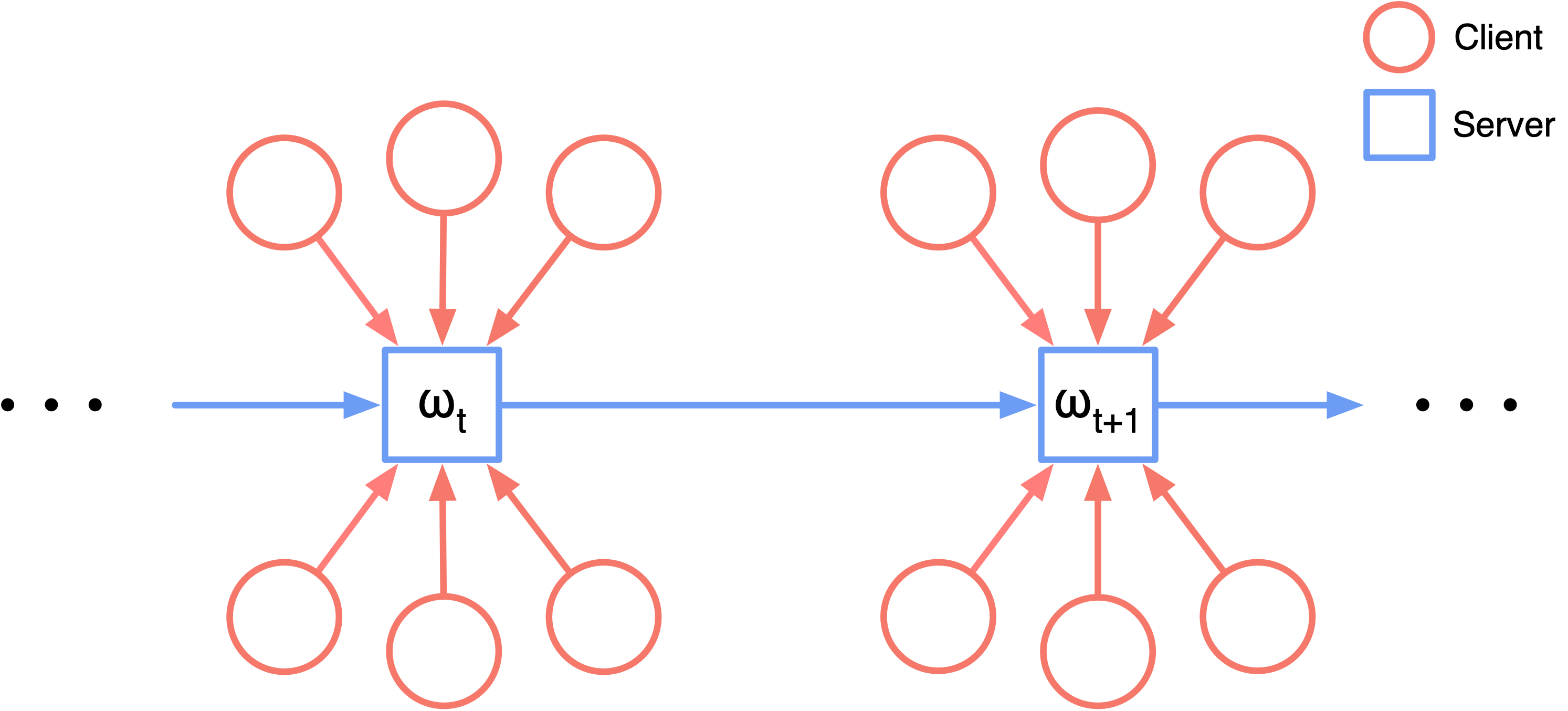
Federated learning (FL) refers to the learning paradigm that trains machine learning models directly in the decentralized systems consisting of smart edge devices without transmitting the raw data, which avoids the heavy communication costs and privacy concerns. Given the typical heterogeneous data distributions in such situations, the popular FL algorithm \emph{Federated Averaging} (FedAvg) suffers from weight divergence and thus cannot achieve a competitive performance for the global model (denoted as the \emph{initial performance} in FL) compared to centralized methods. In this paper, we propose the local continual training strategy to address this problem. Importance weights are evaluated on a small proxy dataset on the central server and then used to constrain the local training. With this additional term, we alleviate the weight divergence and continually integrate the knowledge on different local clients into the global model, which ensures a better generalization ability. Experiments on various FL settings demonstrate that our method significantly improves the initial performance of federated models with few extra communication costs.
PDF Abstract

 CIFAR-10
CIFAR-10
 MNIST
MNIST
