Contrastive Learning of Semantic and Visual Representations for Text Tracking
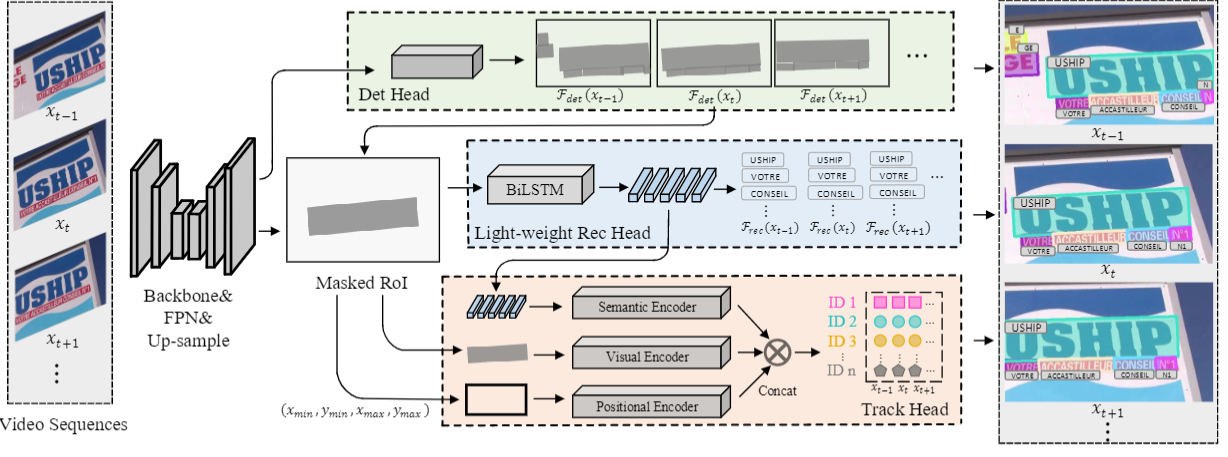
Semantic representation is of great benefit to the video text tracking(VTT) task that requires simultaneously classifying, detecting, and tracking texts in the video. Most existing approaches tackle this task by appearance similarity in continuous frames, while ignoring the abundant semantic features. In this paper, we explore to robustly track video text with contrastive learning of semantic and visual representations. Correspondingly, we present an end-to-end video text tracker with Semantic and Visual Representations(SVRep), which detects and tracks texts by exploiting the visual and semantic relationships between different texts in a video sequence. Besides, with a light-weight architecture, SVRep achieves state-of-the-art performance while maintaining competitive inference speed. Specifically, with a backbone of ResNet-18, SVRep achieves an ${\rm ID_{F1}}$ of $\textbf{65.9\%}$, running at $\textbf{16.7}$ FPS, on the ICDAR2015(video) dataset with $\textbf{8.6\%}$ improvement than the previous state-of-the-art methods.
PDF Abstract

 ICDAR 2013
ICDAR 2013
 COCO-Text
COCO-Text
