Controllable Text-to-Image Generation
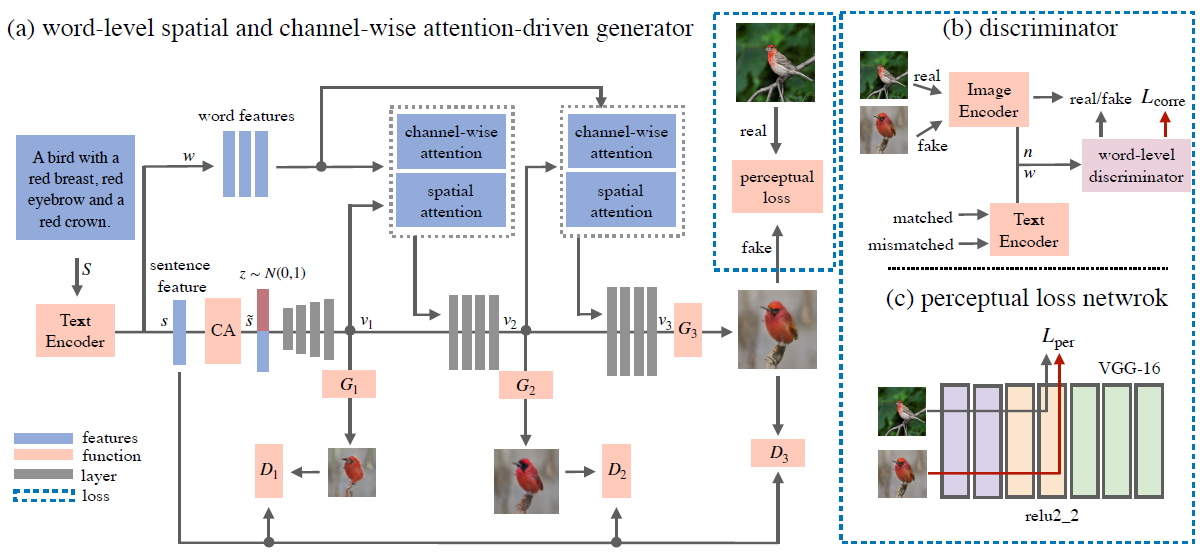
In this paper, we propose a novel controllable text-to-image generative adversarial network (ControlGAN), which can effectively synthesise high-quality images and also control parts of the image generation according to natural language descriptions. To achieve this, we introduce a word-level spatial and channel-wise attention-driven generator that can disentangle different visual attributes, and allow the model to focus on generating and manipulating subregions corresponding to the most relevant words. Also, a word-level discriminator is proposed to provide fine-grained supervisory feedback by correlating words with image regions, facilitating training an effective generator which is able to manipulate specific visual attributes without affecting the generation of other content. Furthermore, perceptual loss is adopted to reduce the randomness involved in the image generation, and to encourage the generator to manipulate specific attributes required in the modified text. Extensive experiments on benchmark datasets demonstrate that our method outperforms existing state of the art, and is able to effectively manipulate synthetic images using natural language descriptions. Code is available at https://github.com/mrlibw/ControlGAN.
PDF Abstract NeurIPS 2019 PDF NeurIPS 2019 Abstract




 MS COCO
MS COCO
 CUB-200-2011
CUB-200-2011
 Multi-Modal CelebA-HQ
Multi-Modal CelebA-HQ

